 Amikor Mira Muratit, az OpenAI főmérnökét a Wall Street Journal arról faggatta, hogy milyen adatokat használtak a szövegből videót generáló Sora csúcsmodell trenírozásához, a CTO mellébeszélt.
„Egy alkotónak elvárásai vannak, ha feltölti kemény munkájának gyümölcsét a platformunkra. Ezek egyike a…
Amikor Mira Muratit, az OpenAI főmérnökét a Wall Street Journal arról faggatta, hogy milyen adatokat használtak a szövegből videót generáló Sora csúcsmodell trenírozásához, a CTO mellébeszélt.
„Egy alkotónak elvárásai vannak, ha feltölti kemény munkájának gyümölcsét a platformunkra. Ezek egyike a…
Az Neumann Társaság blogja a legfejlettebb infokom technológiákról
Jelenből a Jövőbe
Nyelvtanulás másként
 A gépitanulás-modellek jellegzetesen olyan feladatokon gyakorolva tanulnak nyelveket, hogy egy adott szövegben előre kell jelezniük a következő szót. A Stanford Egyetem két kutatója viszont kevésbé fókuszált, inkább emberi módon trenírozott egy nyelvmodellt.
A nyelvet indirekt módon, szöveges…
A gépitanulás-modellek jellegzetesen olyan feladatokon gyakorolva tanulnak nyelveket, hogy egy adott szövegben előre kell jelezniük a következő szót. A Stanford Egyetem két kutatója viszont kevésbé fókuszált, inkább emberi módon trenírozott egy nyelvmodellt.
A nyelvet indirekt módon, szöveges…
Humán kollégáinál is jobban szintetizált vegyszereket az amszterdami robotvegyész
 Az Amszterdami Egyetem kutatói fényre aktiválódó vegyi reakciók tervezését megtanuló robotikus rendszert fejlesztettek. RoboChem úgy végzi munkáját, hogy optimális eredményt ér el vele, kémiai anyagok szintetizálásában humán kollégáit is felülmúlta.
A rendszer több elemből áll össze.
A…
Az Amszterdami Egyetem kutatói fényre aktiválódó vegyi reakciók tervezését megtanuló robotikus rendszert fejlesztettek. RoboChem úgy végzi munkáját, hogy optimális eredményt ér el vele, kémiai anyagok szintetizálásában humán kollégáit is felülmúlta.
A rendszer több elemből áll össze.
A…
Mit tanulhat a mesterséges intelligencia egy csecsemőtől?
 Csecsemők velük született adottságaik miatt értik a világunkat irányító fizikát, új fogalmakat és a nyelvet akkor is gyorsan megtanulják, ha korlátozott információ áll rendelkezésükre.
Még a mai legfejlettebb mesterségesintelligencia-rendszereknek sincsenek meg ezek a képességeik. A nyelvmodellek…
Csecsemők velük született adottságaik miatt értik a világunkat irányító fizikát, új fogalmakat és a nyelvet akkor is gyorsan megtanulják, ha korlátozott információ áll rendelkezésükre.
Még a mai legfejlettebb mesterségesintelligencia-rendszereknek sincsenek meg ezek a képességeik. A nyelvmodellek…
A New York Times beperelte az OpenAI-t és a Microsoftot
 A mesterségesintelligencia-modellek egyre több vitát kavarnak, és mind gyakrabban hozzák fel ellenük sajtóanyagok, cikkek, irodalmi munkák jogtalan felhasználását. Ezeken az anyagokon trenírozzák őket, minél több adatot használ egy nagy nyelvmodell (LLM), annál hatékonyabb és pontosabb lesz, annál…
A mesterségesintelligencia-modellek egyre több vitát kavarnak, és mind gyakrabban hozzák fel ellenük sajtóanyagok, cikkek, irodalmi munkák jogtalan felhasználását. Ezeken az anyagokon trenírozzák őket, minél több adatot használ egy nagy nyelvmodell (LLM), annál hatékonyabb és pontosabb lesz, annál…
Hogyan találja meg a robot a kulcscsomómat?
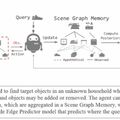 A funkciótervezés az adatmegjelenítés legjobb módjának kitalálása, hogy aztán egy mesterségesintelligencia-modell tanulhasson belőle. A Stanford Egyetem kutatói az időhöz kapcsolódó jellemzőket használva tették lehetővé modelljüknek, hogy megtanulja: a gráfok időben változnak.
Ilyen jellemző lehet…
A funkciótervezés az adatmegjelenítés legjobb módjának kitalálása, hogy aztán egy mesterségesintelligencia-modell tanulhasson belőle. A Stanford Egyetem kutatói az időhöz kapcsolódó jellemzőket használva tették lehetővé modelljüknek, hogy megtanulja: a gráfok időben változnak.
Ilyen jellemző lehet…
Gépi tanulással szűk térben is jól csomagolnak a robotok
 Ha próbáltunk már a családi nyaralásra elegendő cuccot autónk csomagtartójába pakolni, tudjuk, hogy nehéz feladat. Az emberhez hasonlóan, robotoknak is meggyűlik a bajuk a „sűrű” csomagolással.
Robotok számára a csomagolási probléma megoldása számos feltétellel jár: csomagok egymásra rakása, hogy a…
Ha próbáltunk már a családi nyaralásra elegendő cuccot autónk csomagtartójába pakolni, tudjuk, hogy nehéz feladat. Az emberhez hasonlóan, robotoknak is meggyűlik a bajuk a „sűrű” csomagolással.
Robotok számára a csomagolási probléma megoldása számos feltétellel jár: csomagok egymásra rakása, hogy a…
Hatékonyabban gyakoroltat robotokat a Toyota
 A Toyota Kutatóintézet (TRI) generatív mesterségesintelligencia-módszerével új és javított ügyesség-készségeket gyorsan, hatékonyan lehet robotoknak megtanítani. Az intézet szerint megközelítésük sokat segít a robot-ember együttműködésben, robot-ember közös munkavégzésében.
Elmondták, hogy a…
A Toyota Kutatóintézet (TRI) generatív mesterségesintelligencia-módszerével új és javított ügyesség-készségeket gyorsan, hatékonyan lehet robotoknak megtanítani. Az intézet szerint megközelítésük sokat segít a robot-ember együttműködésben, robot-ember közös munkavégzésében.
Elmondták, hogy a…
Hogyan csökkenthető a gépi tanulásra elhasznált energiamennyiség?
 Gépi tanulást energiafogyasztásra vonatkozó döntéshozásra használó kerettel akár hatvan százalékkal csökkenthető az energiahasználat, miközben a nagy szerverekben és szuperszámítógépeknél világszerte alkalmazott többmagos processzorokban nem romlik a számítási teljesítmény.
A Washington Állami…
Gépi tanulást energiafogyasztásra vonatkozó döntéshozásra használó kerettel akár hatvan százalékkal csökkenthető az energiahasználat, miközben a nagy szerverekben és szuperszámítógépeknél világszerte alkalmazott többmagos processzorokban nem romlik a számítási teljesítmény.
A Washington Állami…
Elfogultak-e a gépilátás-rendszerek?
 A Meta, a Facebook anyacége nyílt forrású adatsort tett közzé, hogy tesztelhető legyen a fényképeken és videókon objektumokat észlelő és csoportosítható gépilátás-modellek elfogultsága.
A „Korrektség a gépi látás kiértékelésében” (FAirness in Computer Vision EvaluaTion), a FACET (aspektus) 32 ezer…
A Meta, a Facebook anyacége nyílt forrású adatsort tett közzé, hogy tesztelhető legyen a fényképeken és videókon objektumokat észlelő és csoportosítható gépilátás-modellek elfogultsága.
A „Korrektség a gépi látás kiértékelésében” (FAirness in Computer Vision EvaluaTion), a FACET (aspektus) 32 ezer…