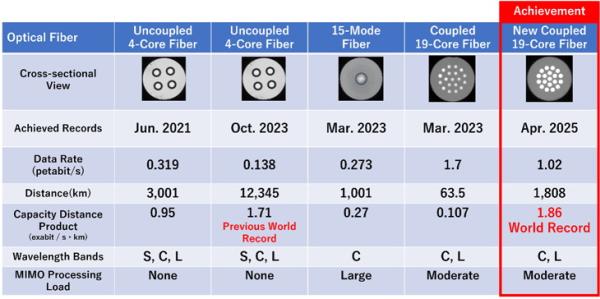
Az Apple mesterségesintelligencia-fejlesztésekben ugyan lemaradt a vetélytársaktól, az iOS feletti kontrollja viszont komoly előny. Ha az operációs rendszer egy bizonyos modellel érkezik, és alapértelmezettként tölti be a korlátozott memóriába, a fejlesztők sokkal nagyobb ösztönzést éreznek az „iOS-kompatiblis” modell, s nem az alternatívák használatára.
A telefonok korlátozott memóriája és a jó modellek nagy mérete miatt sok alkalmazásfejlesztő számára egyáltalán nem praktikus szoftveréhez modellt mellékelni. Azaz, ha az Apple támogatja a modellt, valószínűleg jelentős mértékben elterjed az eszközökön (on-device) történő használata. (Ugyanez persze az Androidra is érvényes.)
Az Apple régóta ígéri a Siri MI-asszisztens frissítését, de az folyamatosan késik, illetve messzire nem vezető, korlátozott ráncfelvarrásokat végeznek rajta. És ez csak a Siri… A Google és Android platformja egyértelműen előnyben van. Az almás cég, ha megkésve is, de a tavaly bevezette Apple Alapmodellek (Apple Foundation Models, AFM) keretet, most pedig a frissítésével reagált.
A családba eszközökön használt kisebb és szervereken hosztolt nagyobb modellek egyaránt tartoznak. Kapacitásaikat bővítették, sebességüket és hatékonyságukat növelték. Az AFM-keret, egy alkalmazásprogramozói felület (API) kiadásával a fejlesztők az eszközökön működő modelleket minden olyan Apple hardveren használhatják ezentúl, amelyeken az AFM engedélyezett.
Az input szöveg- és kép- (maximum 65 ezer tokenig), az output szövegalapú. Az on-device modellek transzformer neurális hálói hárommilliárd, vizuális transzformerei 300 millió paraméteresek. A nyilvánosság számára nem elérhető AFM-szerveren lévő, egyedire kialakított „szekértők keveréke” (mixture-of-experts) transzformer méretét nem tették közzé, míg a vizuális egymilliárd paraméteres.
A tizenöt nyelven működő család nagyon jó a nem amerikai angol és a képmegértésben. A gyakorló adatkészletről, a kiértékelő protokollról, a látás-adapter architektúrájáról és az output tokenek korlátjáról a nagyvállalat nem tett közzé infókat.
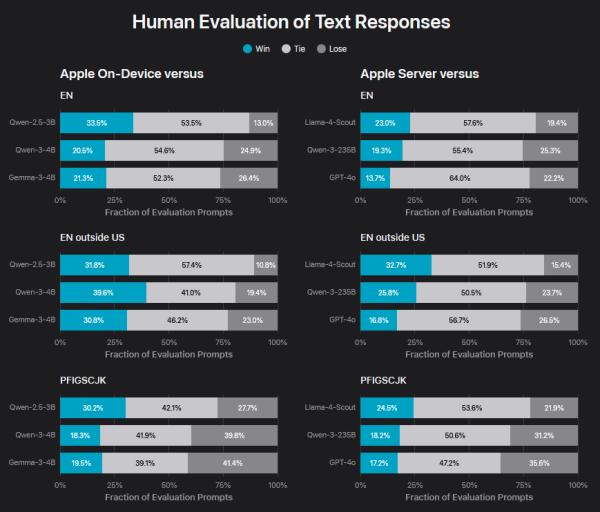
A hasonló méretű vagy nagyobb modellekkel megmérettetve, az AFM-modellek (az ábrán látható) felemás teljesítményt értek el a nyelvi feladatokból álló teszteken.