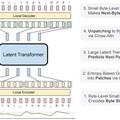
 A Meta, a Washingtoni és a Chicagói Egyetem kutatói Byte Latent Transformer (BLT) nevű, frissen fejlesztett rendszere közvetlenül, bájtok formájában dolgozza fel szövegkarakterek csoportjait.
A modell jobban kezeli az olyan zajos inputokat, mint a helyesírási hibák vagy az elütések,…
A Meta, a Washingtoni és a Chicagói Egyetem kutatói Byte Latent Transformer (BLT) nevű, frissen fejlesztett rendszere közvetlenül, bájtok formájában dolgozza fel szövegkarakterek csoportjait.
A modell jobban kezeli az olyan zajos inputokat, mint a helyesírási hibák vagy az elütések,…
Az Neumann Társaság blogja a legfejlettebb infokom technológiákról
Jelenből a Jövőbe
Nagy táblázatokat is olvasnak a nagy nyelvmodellek
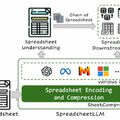 A nagy nyelvmodellek (LLM) kis táblázatokat feldolgoznak, de nagyobbakkal meggyűlik a bajuk, mert túl méretes az input.
A Microsoft kutatói táblázattömörítő megoldást javasolnak, így LLM-ek is képesek azonosítani azokat, vizsgálhatják speciális kérdéseket megválaszoló részeiket.
A legtöbb…
A nagy nyelvmodellek (LLM) kis táblázatokat feldolgoznak, de nagyobbakkal meggyűlik a bajuk, mert túl méretes az input.
A Microsoft kutatói táblázattömörítő megoldást javasolnak, így LLM-ek is képesek azonosítani azokat, vizsgálhatják speciális kérdéseket megválaszoló részeiket.
A legtöbb…
A világ leggyorsabb mesterségesintelligencia-platformja
 A SambaNova Systems a Llama 3.1 405B (a B a milliárd paraméter rövidítése) modelljét a versenytársaknál jóval gyorsabban futtató felhőszámítás-szolgáltatást indított. Elérhető egy ingyenes és fizetős (vállalkozás) szint is, a szintén fizetős fejlesztői szint év végéig startol.
A vállalat…
A SambaNova Systems a Llama 3.1 405B (a B a milliárd paraméter rövidítése) modelljét a versenytársaknál jóval gyorsabban futtató felhőszámítás-szolgáltatást indított. Elérhető egy ingyenes és fizetős (vállalkozás) szint is, a szintén fizetős fejlesztői szint év végéig startol.
A vállalat…
Megmagyarázható lesz a nagy nyelvmodellek működése
 A mai mesterségesintelligencia-fejlesztések alapja, a nagy nyelvmodellek (large language models, LLM) működése sok kérdést vet fel, mert nem értjük teljesen. Miként változtatja meg a modell finomhangolása a bemenetek megjelenítését? Mi történik a modell belsejében a gondolati láncra felépített…
A mai mesterségesintelligencia-fejlesztések alapja, a nagy nyelvmodellek (large language models, LLM) működése sok kérdést vet fel, mert nem értjük teljesen. Miként változtatja meg a modell finomhangolása a bemenetek megjelenítését? Mi történik a modell belsejében a gondolati láncra felépített…
A Gemini AI-val hasznosabbak az irodai robotok
 Google-kutatók a természetesnyelv-feldolgozást és a gépi látást összekombinálva, új eszközt fejlesztettek robotok navigációjához: szöveges promptok és vizuális inputok alapján, belső térben történő tájékozódásra tanítottak meg egyet.
Robotok navigációjához a környezet feltérképezése mellett…
Google-kutatók a természetesnyelv-feldolgozást és a gépi látást összekombinálva, új eszközt fejlesztettek robotok navigációjához: szöveges promptok és vizuális inputok alapján, belső térben történő tájékozódásra tanítottak meg egyet.
Robotok navigációjához a környezet feltérképezése mellett…
Dokumentált dezinformáció
 A mesterséges intelligencia által létrehozott dezinformáció, főként képek, videók és hanganyagok száma folyamatosan nő, 2023 végén már a számítógéppel manipulált médiatartalmak több mint harminc százalékáért MI volt a felelős.
A realisztikus anyagokat generáló MI-modellek széleskörű elérhetőségével…
A mesterséges intelligencia által létrehozott dezinformáció, főként képek, videók és hanganyagok száma folyamatosan nő, 2023 végén már a számítógéppel manipulált médiatartalmak több mint harminc százalékáért MI volt a felelős.
A realisztikus anyagokat generáló MI-modellek széleskörű elérhetőségével…
Nehezen tanulnak kínai szövegeken a mesterségesintelligencia-modellek
 A multimodális GPT-4o-val hanggal, szöveggel, videóval interakcióba léphetünk. A modell megjelenése utáni napokban viszont több probléma felmerült az OpenAI csúcstermékével kapcsolatban.
Scarlett Johansson például hangja jóváhagyása nélküli utánzásával vádolta a céget. Aztán kiderült, hogy a…
A multimodális GPT-4o-val hanggal, szöveggel, videóval interakcióba léphetünk. A modell megjelenése utáni napokban viszont több probléma felmerült az OpenAI csúcstermékével kapcsolatban.
Scarlett Johansson például hangja jóváhagyása nélküli utánzásával vádolta a céget. Aztán kiderült, hogy a…
Mennyire pontosan válaszolnak nagy nyelvmodellek professzionális szintű lekérdezésekre?
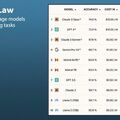 Sok pénzügyi szakember és jogász dokumentumok feldolgozásától kamatlábak előrejelzéséig, változatos célokra használ nagy nyelvmodell-alkalmazásokat. Ezekben az esetekben azonban kitüntetett fontosságú az output felügyelete, mert a tévedések súlyos következményekkel járhatnak.
A mesterséges…
Sok pénzügyi szakember és jogász dokumentumok feldolgozásától kamatlábak előrejelzéséig, változatos célokra használ nagy nyelvmodell-alkalmazásokat. Ezekben az esetekben azonban kitüntetett fontosságú az output felügyelete, mert a tévedések súlyos következményekkel járhatnak.
A mesterséges…
Jön az Apple nagy nyelvmodellje, félhet a ChatGPT
 Az Apple eddig kimaradt a ChatGPT-vel jelképezett mesterségesintelligencia-forradalomból, a generatív MI diadalútjából, a nagy nyelvmodellek (large language models, LLM) fejlesztéséből. Tavaly már röppentek fel hírek változásokról, hogy az almás cég bekapcsolódna a versenybe, nagy titokban folyó…
Az Apple eddig kimaradt a ChatGPT-vel jelképezett mesterségesintelligencia-forradalomból, a generatív MI diadalútjából, a nagy nyelvmodellek (large language models, LLM) fejlesztéséből. Tavaly már röppentek fel hírek változásokról, hogy az almás cég bekapcsolódna a versenybe, nagy titokban folyó…
Nyelvtanulás másként
 A gépitanulás-modellek jellegzetesen olyan feladatokon gyakorolva tanulnak nyelveket, hogy egy adott szövegben előre kell jelezniük a következő szót. A Stanford Egyetem két kutatója viszont kevésbé fókuszált, inkább emberi módon trenírozott egy nyelvmodellt.
A nyelvet indirekt módon, szöveges…
A gépitanulás-modellek jellegzetesen olyan feladatokon gyakorolva tanulnak nyelveket, hogy egy adott szövegben előre kell jelezniük a következő szót. A Stanford Egyetem két kutatója viszont kevésbé fókuszált, inkább emberi módon trenírozott egy nyelvmodellt.
A nyelvet indirekt módon, szöveges…