 A világ legjobb minőségű, a weben könnyen elérhető szövegeit már összegyűjtötték mesterségesintelligencia-modellek gyakoroltatásához. Így az új anyagok különösen értékessé válnak, ráadásul tudva azt, hogy a modellek mérete és adatétvágya egyre csak nő.
A Harvard bemutatta az egyetem nyilvános…
A világ legjobb minőségű, a weben könnyen elérhető szövegeit már összegyűjtötték mesterségesintelligencia-modellek gyakoroltatásához. Így az új anyagok különösen értékessé válnak, ráadásul tudva azt, hogy a modellek mérete és adatétvágya egyre csak nő.
A Harvard bemutatta az egyetem nyilvános…
Az Neumann Társaság blogja a legfejlettebb infokom technológiákról
Jelenből a Jövőbe
Háborús adatgyűjtemény mesterségesintelligencia-modellek gyakoroltatásához
 Minden jel arra utal, hogy a mesterséges intelligencia kulcsszerepet fog játszani a jövő hadviselésében. Ezt a prognózist szem előtt tartva, elmondható: Ukrajna komoly értéket jelentő forrásanyaggal, sokmillió órányi drónfelvétellel rendelkezik. Az anyagok óriási segítséget jelenthetnek csatatéri…
Minden jel arra utal, hogy a mesterséges intelligencia kulcsszerepet fog játszani a jövő hadviselésében. Ezt a prognózist szem előtt tartva, elmondható: Ukrajna komoly értéket jelentő forrásanyaggal, sokmillió órányi drónfelvétellel rendelkezik. Az anyagok óriási segítséget jelenthetnek csatatéri…
Nyíltforrású adatbázis elektromos járművekhez
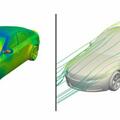 Az MIT (Massachusetts Institute of Technology) mérnökei több mint nyolcezer elektromos jármű tervét hozták létre. Mesterséges intelligenciával összekombinálva, a tervekből a jövőben gyorsan készíthetők járművek.
A DriAerNet++ nyílt forrású adatbázisba gyűjtött tervek a leggyakoribb autótípusokon…
Az MIT (Massachusetts Institute of Technology) mérnökei több mint nyolcezer elektromos jármű tervét hozták létre. Mesterséges intelligenciával összekombinálva, a tervekből a jövőben gyorsan készíthetők járművek.
A DriAerNet++ nyílt forrású adatbázisba gyűjtött tervek a leggyakoribb autótípusokon…
A New York Times beperelte az OpenAI-t és a Microsoftot
 A mesterségesintelligencia-modellek egyre több vitát kavarnak, és mind gyakrabban hozzák fel ellenük sajtóanyagok, cikkek, irodalmi munkák jogtalan felhasználását. Ezeken az anyagokon trenírozzák őket, minél több adatot használ egy nagy nyelvmodell (LLM), annál hatékonyabb és pontosabb lesz, annál…
A mesterségesintelligencia-modellek egyre több vitát kavarnak, és mind gyakrabban hozzák fel ellenük sajtóanyagok, cikkek, irodalmi munkák jogtalan felhasználását. Ezeken az anyagokon trenírozzák őket, minél több adatot használ egy nagy nyelvmodell (LLM), annál hatékonyabb és pontosabb lesz, annál…
Százszor energiahatékonyabb lett a mesterséges intelligencia
 Az Illinois állambeli Északnyugati Egyetemen új nanoelektromos eszközt fejlesztettek gépitanulás-alapú osztályozó feladatok valóban energiahatékony megvalósítására. Az eszköz a jelenlegi technológiák fogyasztásának századrészét használva hatalmas adatmennyiség feldolgozására,…
Az Illinois állambeli Északnyugati Egyetemen új nanoelektromos eszközt fejlesztettek gépitanulás-alapú osztályozó feladatok valóban energiahatékony megvalósítására. Az eszköz a jelenlegi technológiák fogyasztásának századrészét használva hatalmas adatmennyiség feldolgozására,…
Elfogultak-e a gépilátás-rendszerek?
 A Meta, a Facebook anyacége nyílt forrású adatsort tett közzé, hogy tesztelhető legyen a fényképeken és videókon objektumokat észlelő és csoportosítható gépilátás-modellek elfogultsága.
A „Korrektség a gépi látás kiértékelésében” (FAirness in Computer Vision EvaluaTion), a FACET (aspektus) 32 ezer…
A Meta, a Facebook anyacége nyílt forrású adatsort tett közzé, hogy tesztelhető legyen a fényképeken és videókon objektumokat észlelő és csoportosítható gépilátás-modellek elfogultsága.
A „Korrektség a gépi látás kiértékelésében” (FAirness in Computer Vision EvaluaTion), a FACET (aspektus) 32 ezer…
Hogyan építsünk nagy nyelvmodellekre alkalmazásokat?
 Egyre több nagy nyelvmodell (LLM) nyílt forrású vagy majdnem az, így fejlesztők több opció között választhatnak, hogy hogyan és milyen alkalmazásokat építsenek rájuk.
A legegyszerűbb mód az utasításadás (prompting). Az előzetesen gyakoroltatott LLM-nek utasításokat adva, gyakorlósor nélkül percek,…
Egyre több nagy nyelvmodell (LLM) nyílt forrású vagy majdnem az, így fejlesztők több opció között választhatnak, hogy hogyan és milyen alkalmazásokat építsenek rájuk.
A legegyszerűbb mód az utasításadás (prompting). Az előzetesen gyakoroltatott LLM-nek utasításokat adva, gyakorlósor nélkül percek,…
Az adatcímkézők a mesterségesintelligencia-forradalom elfelejtett hősei
 Fei-Fei Li, a Stanford Egyetem ismert mesterségesintelligencia-kutatója 2007-ben, még a Princeton Egyetemen – a közösségi ötletbörzén (crowdsourcing) alapuló adatannotálás úttörőjeként –, képfelismerő betanításához, a képek számát tízezrekről milliókra növelte. A munkához az Amazon Mechanikus Török…
Fei-Fei Li, a Stanford Egyetem ismert mesterségesintelligencia-kutatója 2007-ben, még a Princeton Egyetemen – a közösségi ötletbörzén (crowdsourcing) alapuló adatannotálás úttörőjeként –, képfelismerő betanításához, a képek számát tízezrekről milliókra növelte. A munkához az Amazon Mechanikus Török…
Elfogynak az adatok
 A big data korában eljuthatunk odáig, hogy a kínálat szintjén nem lesz annyi adat, mint amekkora a kereslet. A paradoxon oka egyszerű és logikus: egyre nehezebb kielégíteni az egyre „nagyobb étkű” gépitanulás-modellek szükségletét.
Az Epoch AI kutatói szerint a szöveges adatokkal már idén bajok…
A big data korában eljuthatunk odáig, hogy a kínálat szintjén nem lesz annyi adat, mint amekkora a kereslet. A paradoxon oka egyszerű és logikus: egyre nehezebb kielégíteni az egyre „nagyobb étkű” gépitanulás-modellek szükségletét.
Az Epoch AI kutatói szerint a szöveges adatokkal már idén bajok…
Annyi az adat, hogy új mértékegységek kellettek
 Egyre több digitális adatot hozunk létre és tárolunk, és a folyamatosan növekvő számokkal csak akkor tudjuk tartani a lépést, ha új mértékegységeket találunk ki.
Ennek az alapvetésnek a szellemében, a 27. Általános Súly- és Mértékkonferencián, november 19-én úgy döntöttek, hogy a Nemzetközi…
Egyre több digitális adatot hozunk létre és tárolunk, és a folyamatosan növekvő számokkal csak akkor tudjuk tartani a lépést, ha új mértékegységeket találunk ki.
Ennek az alapvetésnek a szellemében, a 27. Általános Súly- és Mértékkonferencián, november 19-én úgy döntöttek, hogy a Nemzetközi…