A mélytanulás (deep learning) technikákkal a kiváló minőségű és jól felcímkézett adatok, adatsorok nélkülözhetetlenek a gépitanulás-projektek sikeréhez. Hagyományosan az adatoknak vagy a modell tanításának helyén, azaz a gépen vagy adatközpontban kell lenniük.
A Google biztonságos és robusztus, felhőalapú Egyesített Tanulás (Federated Learning) architektúrája ennek a gyakorlatnak vethet véget. Az architektúrát ugyanis a felhasználók mobileszközökön folytatott interakciói alapján gyakorló modellekre találták ki.
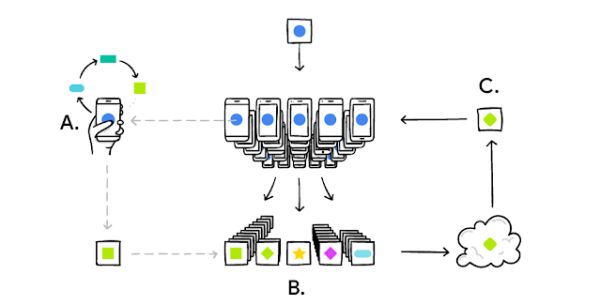
Készülékünk letölti az aktuális modellt, az a telefonon lévő adatokból tanul, javul, majd összefoglalót készít újonnan szerzett ismereteiből. Frissíti magát, és a számítási felhőbe csak az a titkosított formában továbbított frissítés jut el. A többi user frissítéseivel összevetve, azonnal javul a megosztott modell minősége. A gyakorlóadatok készülékünkön maradnak, és a felhőben semmiféle egyéni, személyes frissítést nincs tárolva.
Így az új architektúra okosabb modelleket eredményez, kisebb a késleltetés, kevesebb az áramfogyasztás, és a személyes adatokat sem fenyegeti veszély. Maga az architektúra is frissíti a megosztott modellt, amelynek újabb és jobb minőségű változatát azonnal használhatjuk készülékünkön.
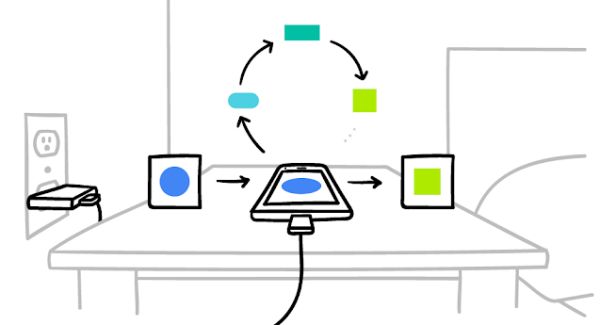
Az eredmény: jelentős mértékben javul a felhasználói élmény. A rendszert – a népszerű Google Keyboarddal (Gboard) – Androidon már tesztelték is.
A fejlesztőknek több algoritmikus kihívást kellett megoldaniuk.
A gépitanulás-rendszereken futó optimalizáló algoritmusok óriási adatsorokkal dolgoznak. Az adatsorok szétosztása általában homogén módon történik a felhőben lévő szerverek között. Sok masszívan iteratív algoritmus alacsony késleltetéssel és zökkenőmentesen fér hozzá a tanulóadatokhoz. Az új rendszerben viszont többmillió készülék között, heterogén módon oszlanak meg az adatok, szignifikánsan magasabb késleltetéssel, nehezebb hozzáféréssel, és csak időszakosan, gyakorlásra érhetők el.
A rendszer Gboardot futtató többmillió különféle készüléken való gördülékeny működéséhez fejlett technológiákat kellett alkalmazni. A gyakorlás például ezért történik a TensorFlow (a Google gépitanulás-algoritmusok leírására és végrehajtására használt nyílt forrású szoftverkönyvtára) kicsit „lebutított” verziójával. Mivel a feltöltés sokkal lassabb a letöltésnél, a kutatóknak az utóbbit is fel kellett gyorsítaniuk.
Szerintük még csak a felszínt kapirgálják, ráadásul az Egyesített Tanuláshoz új eszközök mellett újfajta problémamegoldás is kell. Elterjedését egyes tényezők (nincs közvetlen hozzáférés a nyers adatokhoz, kommunikációs költségek stb.) hátráltathatják, komoly előnyei – készülékünk „okosabb” lesz – viszont a technikai kihívások leküzdésére ösztökélik a felhasználókat.