Tanárok valószínűleg nem örülnek a következő állításnak, de az állítás az érthető idegenkedés ellenére is igaz – dolgozatoknál néha akkor adjuk a legjobb válaszokat, ha egyszerűen lemásoljuk a szomszédét.
A Facebook mesterségesintelligencia-fejlesztő csoportja és a Stanford Egyetem kutatói új nyelvimodell-keretet dolgoztak ki ilyen jellegű, kontextuális előrejelzésekre. Jelen esetben befejezetlen, hiányos mondat következő szavára való következtetést értik előrejelzésen. A kNN-LM nevű algoritmust a gépi tanulásban bevett módszerrel, gyakorlóadatokon trenírozták hozzá.
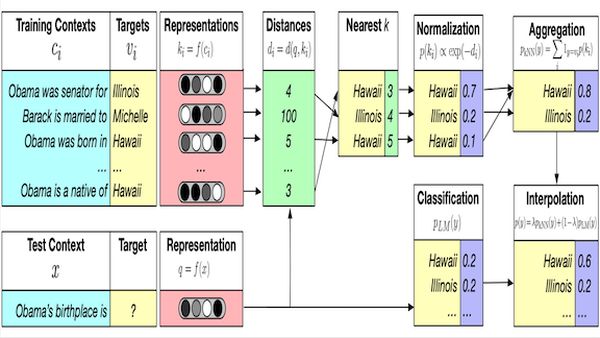
A probléma lényege, hogy egy modellnek egyelőre sokkal könnyebb két hasonló jelentésű mondattöredéket azonosítania, mint a mondatokat (helyesen) kiegészíteni, befejezni.
Ha adott a mondattöredék, és az MI-nek meg kell mondania a következő szavakat, akkor a töredékhez hasonló mondatokat keres a gyakorlósorban, és az általa talált példákat használja majd a következtetéshez. (Lényegében, lelesi, hogy a szomszédok mit írtak.)
A modell például a „Dickens írta a ...” kezdetű mondatot úgy fejezheti be, hogy „Dickens írta a Twist Olivért.” A gyakorlóadatok alapján az MI tudja, hogy a „Twist Olivér” helyes válasz lehet.
A fejlesztők előzetes gyakorláson átesett modellt javasolnak, a gyakorlómondatok vektoros megjelenítésével, míg a tesztmondatok elemzésénél algoritmus kombinálja össze az információkat. A megközelítés minden előzetesen trenírozott nyelvi modellel működik, a legtöbb kísérlethez azonban speciális hálózatokat használtak.
Első lépésben a kNN-LM a gyakorlósor összes mondatához vektoros megjelenítést generál, majd az új input mondathoz megkeresi ugyanezen vektorok legközelebbi („szomszédos”) megjelenítését. Minél közelebbi egy gyakorlóvektor az inputhoz, annál magasabb pontszámot ér el („jobban súlyozódik”) a gyakorlószekvencia következő lépésében. A nyelvi modell az input következő jegyét előre is jelzi.
Ezt követően az MI végső következtetéséhez a legközelebbi vektoros és a modell általi előrejelzést egyaránt figyelembe veszi. Különleges mérés minősíti, hogy mennyire ragaszkodik az egyikhez, illetve a másikhoz.
AWikipédia-szócikkeken tesztelt algoritmus 10 százalékkal jobban teljesített, mint az eddigi legmodernebb nyelvi modellek. A modell jelenlegi gyengéje, hogy hatalmas számítási kapacitásra van szüksége.