A Meta, a Washingtoni és a Chicagói Egyetem kutatói Byte Latent Transformer (BLT) nevű, frissen fejlesztett rendszere közvetlenül, bájtok formájában dolgozza fel szövegkarakterek csoportjait.
A modell jobban kezeli az olyan zajos inputokat, mint a helyesírási hibák vagy az elütések, intelligensebben viszonyul a karakterszintű információkhoz, például, hogy hány r betű van az angol strawberry (eper) szóban. Potenciálisan jobban érti az ismerős nyelvekkel elvileg betűcsoportokat megosztó, kevésbé ismert, ritkábban használt nyelveket.
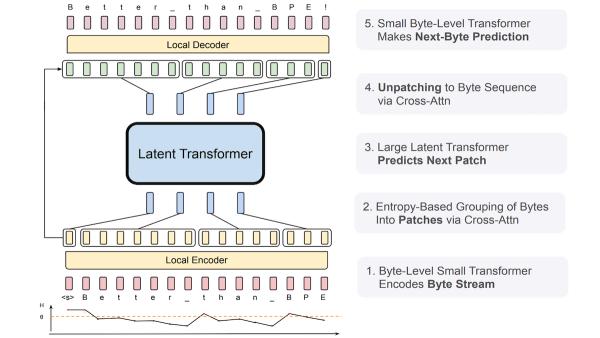
Megközelítésük lényege tokenesítés helyett az input karakterek csoportosítását megtanuló rendszer használata.
A tokenizáló a bájtokat (karaktereket) megtanult szabályok alapján tokenekké – szóvá vagy szórésszé – alakítja; adott sorozatok adott tokenekhez vannak leképezve. Egy nagy nyelvmodell (LLM) hatékonyabb, ha a tokenizálója figyelembe veszi, mennyire könnyű vagy nehéz előrejelezni a következő tokent. Ha képes erre, akkor memóriát és feldolgozási energiát megspórolva, csoportosíthatja a gyakran előforduló tokeneket. Például az „Egyesült Államok fővárosa” kifejezéshez előbb a Washingtont, majd a D-t, a C-t és a pontokat generálja. A „D.C.” utáni token már bonyolultabb, mert sok a működő opció. Kisebb LLM-ek a nehezen megjósolható szöveget kisebb, a könnyebben megjósolhatót nagyobb csoportokba teszik.
Az új modell első szintjén a transzformer inputbájtok szekvenciájából generálja a következő bájtot. A kutatók mérték a bizonytalanságot a bájtcsoportosításhoz, kisebb vagy nagyobb entrópiát állapítottak meg, és a modell bizonytalansága ennek megfelelően változik. A kódoló transzformer megtanulta a csoportokat vektoronként megjeleníteni, míg egy másik transzformer az előző csoportok alapján generálja a következő vektorcsoportot. A vektorok szekvenciájából dekódoló transzformer rekonstruálja a bájtszekvenciát.
A BLT kifejezetten jó eredményt ért el a teszteken. Józanész-kérdésekben és válaszokban megelőzte a Llama 3-at, zajos bemeneteket, különösen karakterek felcserélését és más elírásokat hatékonyabban kezelt, és angol szöveget huszonhat nyelvre (köztük ritka nyelvekre) is jobban fordított.
Mivel közvetlenül bájtokon dolgozik, a BLT természeténél fogva érzékenyebb a nyelvi variációkra.