
A tárgyakat detektáló, felismerő rendszerek általában csak azokkal az objektumokkal boldogulnak, amelyeket a korábbi gyakorlásaikhoz használt adatokban már felcímkéztek. Úgy tűnik, hogy egy új módszerrel könnyebb lesz a munkájuk, és így több tárgyat tudnak a képen belül lokalizálni és felismerni.
A Google Research kutatói által fejlesztett Vision and Language Knowledge Distillation (ViLD) segítségével kialakítható rendszerek olyan tárgyosztályokat is kezelnek, amelyekkel nem gyakoroltak. „Lövés” nélkül detektálják őket (zero-shot object detector).
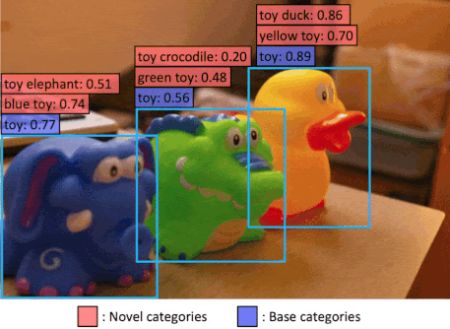
A ViLD munkájához felhasználja egy, hasonló elven működő osztályozó (CLIP) által generált tárgyreprezentációkat.
Adatokból sokszor bonyolult kinyerni az információt, az ismeretek szakszerű megtisztítása („lepárlása”) nélkül nehezen megy. Ez úgy történik, hogy a modell általában megtanulja utánozni egy másik modell outputját. Ehhez hasonlóan, azt is elsajátítja, hogy hogyan utánozzon egy másik által generált reprezentációkat.

A képenként több részt és osztályozást kódoló tárgyfelismerők reprezentációi megegyezhetnek a képenként egyetlen osztályt kódoló osztályozók reprezentációival. A felismerő-modell a több objektumot megjelenítő képek tárgyait, a képen való elhelyezkedésük alapján, különböző részekbe rendezi – vágja ki – az osztályozó számára. A tárgyfelismerő ezt követően tanulja meg, hogy az osztályozó hogyan reprezentálta a részeket (a kép „területi egységeit”).
A korábbi hasonló rendszereket több százmillió kép-szövegpáron gyakoroltatták. A felhasználó megadta nekik a felismerendő osztályok szöveges listáját. A gép kapott egy képet, és a legvalószínűbb tárgyosztályra következtetett belőle.
A Google kutatói szegmentált és felcímkézett tárgyosztályok képein gyakorolt tárgydetektorral bővítettek egy ilyen rendszert. Teljesítményét korábbi megoldásokkal hasonlították össze, és kiderült, hogy pontosabban dolgozik, mint a felügyelet melletti tanuláson (supervised learning) alapuló modellek, azaz a használatban lévő rendszerek zöme.
De miért fontos ez?
Azért, mert a tárgyosztályozó modellek nehezen és drágán tanulnak a nagy és heterogén adatsorokon. A ViLD megoldhatja ezt a problémát, kevesebb képből jobb eredményeket hoz ki, felgyorsítja a munkát.




