A mostani elméletek alapján az ismert univerzumban lévő összes anyag nyolcvanöt százalékát a titokzatos sötét anyag alkotja. Nem bocsát ki, nem nyeli el, nem veri vissza a fényt, nehezen megfogható, így viszont tanulmányozni is rendkívül bonyolult. A csillagászati megfigyelésekben szereplő égitestek és szerkezetek vizsgálatában, jobb megértésükben ez komoly hátrány.
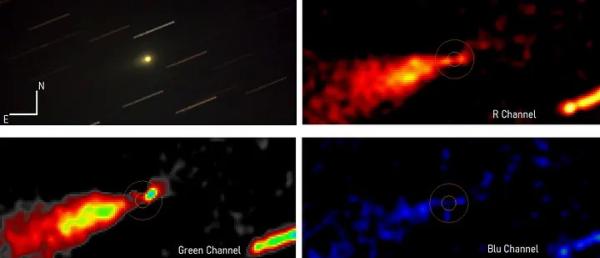
A NASA Hubble űrteleszkópját használó egyik nemzetközi kutatócsoport teljesen új típusú égi objektum felfedezését jelentette be. A Cloud-9 (Felhő-9) szerintük csillagtalan, gázokban gazdag, sötétanyag-felhő. A csillagok hiánya meglepte a tudósokat, és „egy sikertelen galaxis sötétanyag-csontjainak” elnevezett fosszilis maradványra gyanakszanak.

A tudományban általában többet tanulnak a kudarcokból, mint a sikerekből, és mivel nem láttak csillagokat, bizonyítva van a feltevés. A helyi univerzumban egy még meg nem épült galaxis eredeti építőköveit találták meg. A felfedezéssel a sötét anyag is jobban tanulmányozható – magyarázzák a kutatók.
„A felhő a sötét univerzumra nyíló ablak” – jelentette ki Andrew Fox, az egyik tudós.
Vizsgálódásukból az is kiderül, hogy a csillagok tanulmányozásával korlátozott képet kapunk az univerzumról. A köztük tátongó óriási szakadék lehet a megértés kulcsa.
Csillagászok eddig csak elméletben vetették fel egy Cloud-9-szerű objektum létezését. A szokatlan gázfelhő nagyrészt hidrogéngázból áll, és az univerzum nagyon korai napjaira datálható vissza, csakhogy csillagokat nem tartalmaz.
A Hubble teleszkóppal viszont korábban soha nem látott képet kaptak a Földtől 14 millió fényévre lévő csillagtalan régióról. Korábban akár halvány törpegalaxisnak is lehetett volna nézni, a Hubble-val történt megfigyelés után viszont kizárt ez a lehetőség.
A Cloud-9 sokkal kisebb és kompaktabb a környék többi hidrogénfelhőjénél. A „kicsinységet” illetően: a benne lévő hidrogéngáz a Nap tömegének milliószorosa. A kutatók szerint túlnyomó többsége a Nap tömegénél ötmilliárdszor nagyobb sötét anyag.
Ha nagyobb lenne, összeomlott volna, és csillagok születhettek volna belőle. Viszont így is elég nagy a gáz szétszóródásának megakadályozásához, azaz ritka optimális pont. Ráadásul sok hozzá hasonló objektum lehet még a környéken, és valószínűleg mind sikertelen galaxisok sokmillió fényév távolságban szétszóródott maradványai.