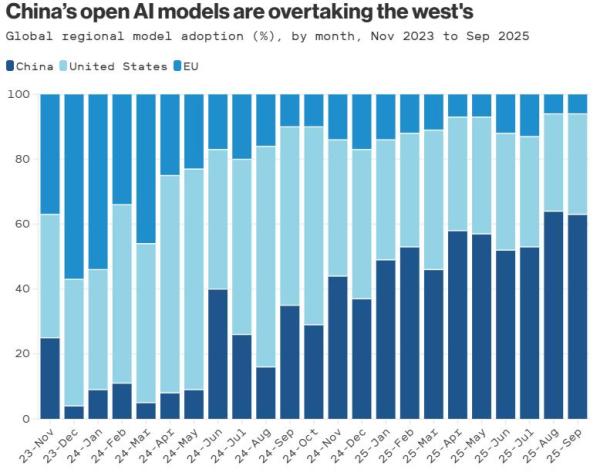
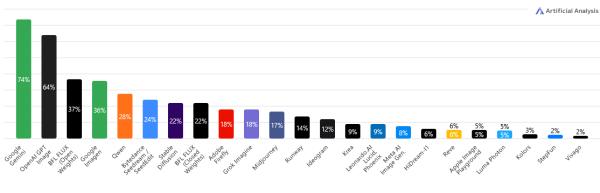
Hogyan tudják a világ egyik, ha nem legfejlettebb mesterséges intelligenciájához, az Anthropic Claude-jához hasonlóan határterületet képviselő modellek a számítógépeken túllépve befolyásolni a fizikai valóságot?
A robotika, a fizikai intelligencia a közeljövő MI-fejlődésének, MI és robotika összekapcsolásának egyik lehetséges, ígéretes útja. A vállalat kutatói kísérleteket végeztek, hogy megfigyeljék, Claude mennyire segít az Anthropic dolgozóinak feladatok robotkutyával történő elvégzésében.

Nyolc kutatót véletlenszerűen két négyes csoportra osztottak. A közleményben kiemelték, hogy egyikük sem robot-szakértő. Az egyik csoport hozzáfért Claude-hoz, a másik nem. Mindkettőnek strandlabdák összegyűjtésére és elhozására kellett négylábú robotokat programoznia.
A Claude csapat több feladatot, átlagban gyorsabban, nagyjából feleannyi idő alatt hajtott végre, mint a másik. Csak ők tettek lényeges lépéseket a végső cél, a labda-összeszedést és elvitelt teljesen autonóm módon végző robot programozása felé.

A mesterséges intelligenciához való hozzáférés a csapatmorált és dinamikát is befolyásolta. A Claude nélkül dolgozók több negatív érzésről és zavarról beszéltek. Emellett többször kérdezték is egymást. A Claude csapat tagjai túlnyomórészt együtt, partnerségben tevékenykedtek a mesterségesintelligencia-modellel.
A kísérlet jelentős fejlődést mutat – az MI komolyan segítheti a robotikai fejlesztéseket, hidat képezhet a digitális és a fizikai világ között. Claude hatékony partnere az embernek. A modellek javulásával javul a fizikai világot befolyásoló képességük is. Ezt a korábban ismeretlen hardverekkel folytatott interakciókkal érik el.
A kísérlet, a hídszerep eljátszása, a peremterületen ténykedő egyre több mesterséges intelligencia azt sugallja, hogy hamarosan megjelenhetnek az ilyen interakciókra alkalmas rendszerek.