Az Intel Bleep (szó szerint: „sípjellel kicenzúráz”) hangfelismerő eszközével chatek automatikusan moderálhatók, lehetővé válik, hogy leállítsuk a ránk zúdított szidalmakat, durva beszédet. Játékokra találták ki, egyelőre a bétaváltozatnál tartanak, azt viszont sikeresen tesztelték, még idén várható a kereskedelmi forgalmazás.
A chipgyártó a tartalommoderáló technológiákat fejlesztő Spirit AI-val dolgozott együtt az új eszközön. A felhasználók finomhangolhatják, hogy egy-egy hangalapú kommunikációból mennyi és milyen típusú durva beszéd jusson el hozzájuk.

A Bleep a beszéddetektálást kombinálja össze a Spirit AI csúcstermékével, amely chatkörnyezetben határozza meg, hogy egy kifejezés, mondat stb. zaklatásnak számít, vagy sem.
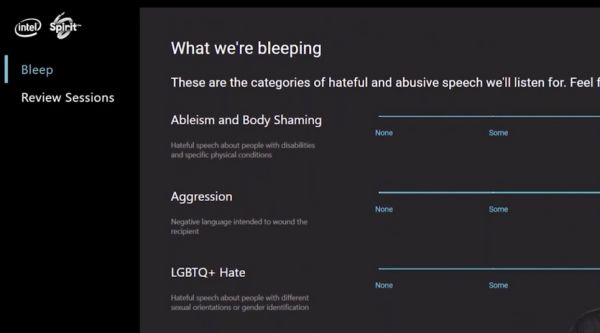
A rendszer kilenc kategória, például a szexuálisan explicit nyelvezet, az LGBTQ-ellenes gyűlöletbeszéd, vagy a nőgyűlölet alapján ítéli meg, mennyire sértő egy szöveg. A felhasználók dönthetnek, hogy egyet sem, többet vagy mindegyiket kiszűrik. A tizedikre, az (afroameriaikra vonatkozó sértő) N-szóra, a rendszer szintén felajánlja az igen/nem választási lehetőséget.
A Bleep egyelőre Windows-PC-ken fut, és mivel közvetlen interakcióban áll a Windows audiokontrollal, sok hangalapú chatalkalmazással működik.
Mások szintén próbálkoznak a játékokban lévő hangkommunikáció, chat önkéntes moderálásával.
A ToxMod moderátoroknak kínál a sértő nyelvezet szervereken átívelő követésére alkalmas kezelőfelületet. A Hive rendszere audió, videó, szöveges és képi tartalmak szűrésére egyaránt alkalmas, egyik ügyfele például a nem kívánt meztelen fotóktól óvja meg az azokra nem kíváncsi felhasználókat. A Two-Hat megoldása a moderálást például szándékos helyesírási hibákkal megtévesztő próbálkozásokat mutatja ki.
A fejlesztéseket a hálózati kommunikáció védelme, a visszaélések és sértegetések nélküli interakció vágya teszi szükségessé. A Rágalmazásellenes Liga felmérése alapján az amerikai online gamerek 22 százaléka azért hagyott abba játékokat, mert verbálisan inzultálták őket.
De még mielőtt cenzúrát kiáltanánk, ne felejtsük el, hogy a moderálásról mi magunk dönthetünk.