
Köztudott, hogy a gépi tanuláshoz használt adatsorokban találhatók hibák. A problémával foglalkozó korábbi vizsgálatok inkább a gyakorlásra, és nem az adatsorokra összpontosítottak. Megállapították, hogy a mélytanuló-rendszerek teljesítménye nem romlik, ha a címkéknek csak kis része pontatlan.
Két fontos tényt azonban figyelembe kell venni. Egyrészt, a hibákban bővelkedő tesztsorok nem igazi mércéi egy modell adottságainak, másrészt, a hibás címkék aránytalanul nagyobb mértékben befolyásolják a méretesebb modelleket.

Sajnos, több referenciaként kezelt adatsorban is akad bőven hibás címke. Számszerűsítve, a tíz leggyakrabban használt 3,4 százalékáról van szó – derül ki két MIT- (Massachusetts Institute of Technology) és egy Amazon-kutató közös tanulmányából. Kiemelik, hogy a rossz címkék negatív hatása a modellek méretének növekedésével párhuzamosan nő.
A legnépszerűbb adatsorok, köztük az ImageNet, az Amazon Reviews és az IMDB hibás címkéinek azonosítására gyakoroltattak be egy modellt. Egy rossz címke két kritériumnak tesz eleget: ha a modell előrejelzett osztályozása nem felel meg a címkének, és ha a modell osztályozásba vetett bizalma nagyobb volt, mint a címkézett osztály előrejelzésével kapcsolatos átlagos bizalma.
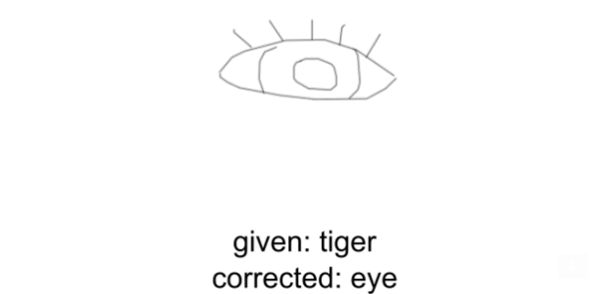
A rosszul címkézett példákat humán „bírálók” is átnézték. Sok egyértelmű hibát találtak, például közönséges békára sütötte rá az MI, hogy macska, vagy egy énekes hanganyagára, hogy fütyörészés, negatív filmkritikákra, hogy pozitív, és így tovább. A QuickDraw idegháló dolgozott a legtöbb, (10,1 százalék), az MNIST a legkevesebb (0,15 százalék) pontatlanul felcímkézett anyaggal.
A kutatók kijavították a címkéket, majd korrigálták a tesztsorokat. Ezt követően mérték, hogy különböző modellek hogyan osztályozták a módosított adatsorokat. A kisebbek sokkal jobban teljesítettek, mint a nagyobbak.
Arra a következtetésre jutottak, hogy a mesterségesintelligencia-fejlesztéseknél ideje lenne a modellközpontú megközelítésről adatközpontúra váltani. Sok csúcsmodell elég jó már ahhoz, hogy az architektúrájával való bíbelődés kevés előnyt hoz, a teljesítmény növelésének legjobb módja viszont egyértelműen a tanulóadatok minőségének feljavítása.




