
Az OpenAI új nyelvmodell-családjának korábbi változatait szándékosan a lépésről lépésre történő gondolkodásra tanították. Matematikában és más tudományokban vagy a kódolásban látványos eredményeket értek el, a felhasználó viszont nem látja a következtetés menetét.
A fizetős ChatGPT felhasználók és API (alkalmazásprogramozói felület) ügyfelek egy része számára már elérhető o1-preview és az o1-mini bétaverzióit megerősítéses tanulással gyakoroltatták, hogy outputjaihoz gondolatláncokat használjon. Az OpenAI egyelőre nem közölte a végső változat kereskedelmi bevezetésének időpontját.
A két modell előzetes változat, az o1-mini gyorsabb, kódolásban különösen hatékony. Méretükről nincs infó, bemeneti kontextus-ablakuk 128 ezer token, csak szövegesekkel dolgoznak, de a tervek szerint a jövőbeli verziók más médiatípusokat is támogatni fognak.
Mindkettőt a webről, nyílt forrású adatbázisokból összeszedett, valamint partnerek által szolgáltatott adatokon trenírozták. Ha az óhajtott következtetési lépéseket generálták, és azok szinkronban voltak emberi értékekkel, célokkal és elvárásokkal, jutalmat kaptak.
Következtető tokeneket dolgoznak fel, amelyekkel a GPT-4o-nál ugyan lassabban és drágábban hoznak létre outputokat, teljesítményük viszont jobb. Az OpenAI rejtve hagyja a gondolatláncot, hogy ne fedje fel a nem-kért információkat. Nem akarják, hogy a felhasználók kontrollálják a modell következtetési mechanizmusát, és nyilvánvalóan el kívánják kerülni azt is, hogy a versenytársak belelássanak az MI elméjébe. A ChatGPT felhasználói mindenesetre elolvashatják az adott válaszhoz vezető lépések összefoglalóját.
Az OpenAI és mások biztonsági szempontból is kiértékelték az outputokat, ügyelve, hogy elkerüljék a nem/gender-, bőrszín- és életkor-alapú elfogultságot, a sértő, káros gondolatláncokat. A két modell kevesebbet is hallucinált, mint a korábbiak, jobban ellenállnak a feltörési kísérleteknek, viszont kockázatosabbak biológiai fenyegetések generálásához, a kockázatok azonban a meghatározott biztonsági keretek között maradnak.
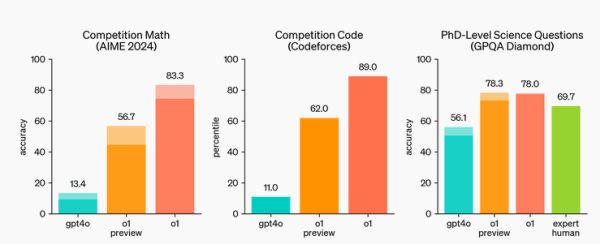
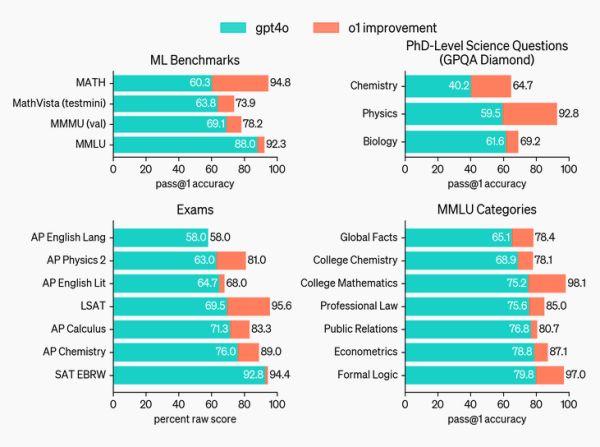
A változatlanul nem-elérhető o1 modell általában jobban teljesített, mint az o1-preview, és (matekban, tudományokban – amerikai történelemben, jogban –, kódolásban) mindkettő jelentősen rávert a GPT-4o-ra.
Az o1 modellek szemléltetik, hogy a megerősítéses tanulás és a gondolatlánc-alapú következtetés kombinációjával az eddigi nagy nyelvmodellek számára problémát okozó feladatok is megoldhatók. Kódolásban sokkal jobbak, és a hibákra „különösen érzékeny” tudományokban is. A gondolatlánc és a következtetés titkosságával viszont ugyanúgy nehezen átláthatók, mint az elődök.




