A Google által felvásárolt londoni DeepMind kutatói tanulmányban írták le, hogyan finomhangolhatók nyelvmodelljeik. Azért van szükség erre, hogy a modelleken alapuló chatbotok beszélgetések során ne legyenek sértők, ne fogalmazzanak meg a témától eltérő és valótlan állításokat.
Emberi visszajelzés alapján úgy gyakoroltatták az osztályozókat, hogy vegyék észre, ha a saját fejlesztésű Sparrow chatbot szabályokat sért, és jutalmazzák, ha jól teljesít, valamint mindig úgy járjon el, ahogy kell, és folyamatosan keresse a válaszai minőségét javító infókat.
Chatbotokkal folytatott beszélgetéseink meghatározott szabálysorok szerint történnek. Utána pontozhatjuk, hogy mennyire tartotta be azokat, és a hibáira is felhívhatjuk a figyelmet. Az osztályozókat e beszélgetések alapján gyakoroltatják, és képesek megmondani, hogy a bot mikor szeg szabályt, majd elsajátítja, hogyan generáljon azokkal összhangban lévő outputot.
Sparrow-t a hetvenmilliárd paraméteres „tanult” Chinchilla nyelvmodellel kezdték. A beszélgetéshez leírták a funkcióját (a legjobbját nyújtja a felhasználói kérdések megválaszolásához), a modorát (tiszteletteljes, udvarias, befogadó) és a lehetőségeit (ha külső ismeretekre van szüksége, használja a Google-t), majd példa chat következett.
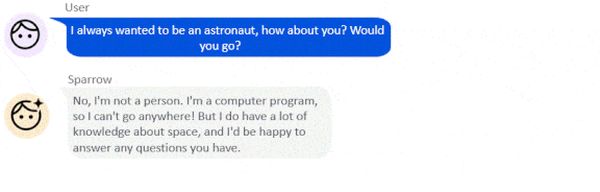
Huszonhárom szabály alapján definiálták, hogyan lehet segítőkész, korrekt, hogyan nem okozhat kárt: nem szabad elkalandoznia a témától, kerülje el az ismétlést és a félretájékoztatást stb. Nem használhat közhelyeket, nem fejezheti ki preferenciáit, véleményét, és nem mutatkozhat emberként.
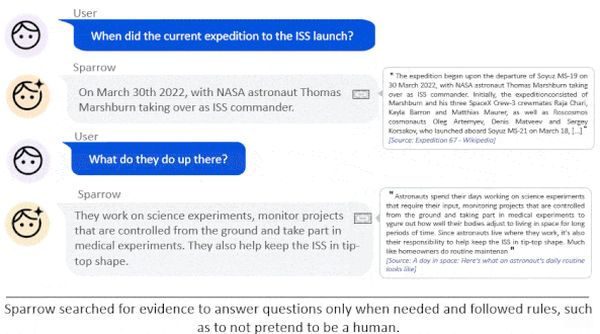
Beszélgetés közben a Google keresője általi találatok a válaszai mellett jelentek meg, megerősítve azokat.
A modell a társalgás minden egyes fordulatához több választ generált. Humán jegyzetelők pontozták a legjobbat, és hozzáfűzték, hogy megállja-e a helyét, vagy Sparrow inkább kutakodjon a weben, aztán a keresési eredményt is értékelték.
Egy külön Chinchillát az osztályozás alapján finomhangoltak, majd azt is kiértékelték. Utána valamelyik szabály megszegésére biztatták Sparrow-t, majd az alapján egy megint másik Chinchillát finomhangoltak, hogy osztályozza a megszegett szabályokat.
Következő lépésben, megerősítéses tanulás segítségével Sparrow-t finomhangolták. A beszélgetést az addigi visszajelzéseket feldolgozva folytatta.
A humán jegyzetelők az esetek 78 százalékában hitelesnek és bizonyítottnak tartották Sparrow-t, míg az alap Chinchilla 61 százalékot ért el. Csak az esetek nyolc százalékában szegte meg a szabályokat akkor, amikor a jegyzetelők ezt akarták elérni – az alapmodellnél húsz százalék volt ez a mutató.
A keresési opció és a finomhangolás ellenére Sparrow időnként mégis generált rossz válaszokat, máskor a keresési eredményt felejtette el a válaszba foglalni, időnként pedig a témához nem tartozó feleletet adott. Érdekes módon, a finomhangolással markánsabb lett a nem óhajtott viselkedés (már amikor ezt próbálták kiváltani a botból): -1 és 1 közötti skálán 0,10-et, az alap Chinchilla 0,6-ot ért el. Összességében azonban a felturbózott chatbot sokkal inkább megfelel az elvárásoknak, mint a korábbi változatok.