A generatív MI ugyan rivaldafényben van, a mesterséges intelligencia felhasználási eseteknek azonban mindössze öt százalékát jelenti. E számok ismeretében mi várható 2025-ben MI-fronton?
Bernard Marr jövőkutató és Bryan Harris, az amerikai multinacionális analitikai és MI-szoftverfejlesztő SAS főmérnöke öt nagy trendet emel ki.

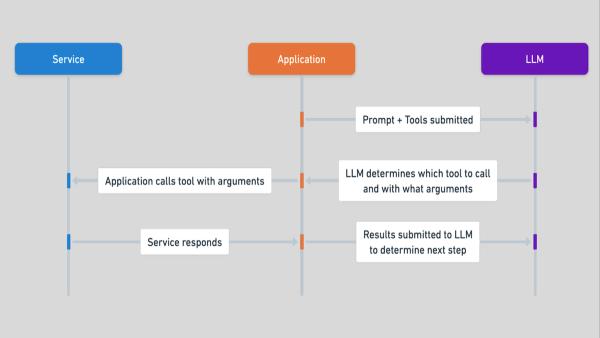
Az MI-modellek eszközből termékké fejlődnek. A nagy nyelvmodellek (LLM-ek) csak a jéghegy csúcsát, a valóvilágbeli alkalmazások kis részét jelentik, de már így is megváltoztatták a mindennapos MI-élményt. Mások is, például amikor gyanús bankkártyás tevékenységről kapunk értesítést, vagy személyes vásárlási ajánlatokkal bombáznak, vagy ha az orvos adataink alapján felír egy receptet. Mindegyik esetben speciális MI-modellek dolgoznak a háttérben. A csalás-detektálástól kezdve a látórendszerek dokumentálásáig, nagyon sok hasonlóra számíthatunk.
A szintetikus adatok a következő MI innovációs hullám motorjai. A minőségi gyakorlóadat iránti kereslet növekedésével egyre jobban terjednek a gyorsan javuló minőségű szintetikus adatok („jó adat nélkül nincs jó MI”). Olyan esetekben, például csalás-detektálásnál különösen hasznosak, amikor egyrészt kevés a valódi adat, másrészt viszont létfontosságú a hatékony MI-rendszerek betanítása. Képzeljük el, hogy a tranzakciók milliói szabályosak, és minimális a csalás. Az algoritmus minősége romlik, amin csak életszerű, de szintetikus adatok, összességében kiegyensúlyozottabb adatkészletek segíthetnek.
Az MI irányítása vezetőségi szintű prioritássá válik. Mesterségesintelligencia-rendszerek egyre több kritikus döntést hoznak, ezért a szervezetek vezetőinek ismerniük kell, hol fut az MI-jük, milyen adatokon gyakoroltatták, és persze a teljesítményét is. Harris négy különálló pillérre (felügyelet, platform, kontroll, kultúra) épülő, átfogó keretrendszert vázol fel. A megfelelő felügyeletet célzott adatetikai gyakorlattal alakítaná ki, a beszámolókat közvetlenül a vezetők kapnák, ők garantálnák, hogy az MI-kezdeményezések kivitelezhetők és morálisan is vállalhatók. A platform lényege a megfelelőség szoftveres infrastruktúrába építése, amellyel az ázsiai, európai és amerikai szabályozásokat is kezelnék. A kontroll a rendszerek folyamatos monitorozása, a hatékonyság nyomon követése. A kultúra kevésbé egyértelmű, de kritikus jelentőségű: nem az algoritmus működését, hanem az MI kockázatait és előnyeit, helyes alkalmazását kell érteni.
A felhőszámítások környezeti lábnyoma, az MI globális széndioxid-kibocsátáshoz való egyre ijesztőbb hozzájárulása, plusz a kiadások növekedése költséghatékonyabb megoldások felé mutat. Első körben az optimalizálás és a fenntartható energiaforrások jöhetnek szóba.
A kvantumszámítás lesz az MI következő nagy „határterülete.” Itt várhatók 2025 legizgalmasabb, legváratlanabb újításai, optimalizálási problémákra (ellátási lánc, gyártás) különösen hatékony megoldásnak ígérkeznek. A kvantumtechnikák speciális MI-problémák megoldásához olyan mértékben járulhatnak hozzá, mint a GPU-k a mélytanulás (deep learning) forradalmához.
Ezek a trendek és konvergenciájuk az MI-lehetőségek új korszakát vetítik előre – prognosztizál Marr és Harris. A siker azonban nemcsak az új technológiák gyors adaptálásától, hanem az adatminőség megbízható alapjaitól és az irányítástól is függ. A minőségi adat komoly versenyelőnyt jelent.