Egy gyógyíthatatlan állapotban lévő marylandi férfinek egy hónapja genetikailag módosított sertésszívet ültettek az eredeti helyére. Kilökődésnek és fertőzésnek eddig semmi jele, ami bizakodásra ad okot. Ilyen műtétet korábban csak egyet hajtottak végre., most – szeptemberben – a 2022-es elsőhöz hasonlóan, a Marylandi Orvosi Egyetem Kórházában került sor rá.
A beteg egészségügyi állapota nem tette lehetővé, hogy emberi szívet ültessenek be neki, és az USA Élelmiszer- és Gyógyszerügyi Hivatala (FDA) megadta az engedélyt a műtétre.
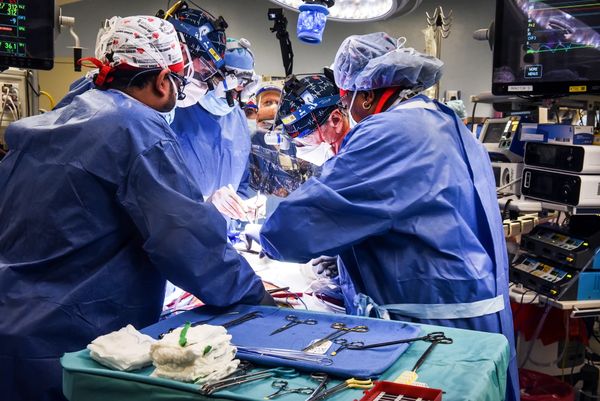
Az ötvennyolc éves Lawrence Faucette új szíve külső segítség nélkül is „jól teljesít”, a levegővétel is önállóan történik. Egy hónap túlélés komoly mérföldkőnek számít, bár a beteg még nincs túl minden veszélyen.
A 2022-es műtét alanya két hónappal a műtét után hunyt el. Több tényező miatt: komplikációk léptek fel, a gyógyszerek károsították a szívet, bár kilökődést nála sem tapasztaltak, a többi belső szerv megtűrte az újat.
A beültetett szervben megbúvó sertésvírusra szintén találtak bizonyítékot, de az orvosok nem tudták eldönteni, hogy a halálesethez volt-e valami köze.
Faucette-et közelről és folyamatosan figyelik, és már leszoktatták az eleinte az új szívet erősító gyógyszerekről. Fizikai terápián is részt vesz, hogy újra járhasson, és visszanyerje erejét.
A kimenettől függetlenül, a műtét és az azóta eltelt egy hónap mindenképpen sikernek tekinthető, több mint százezer, szervbeültetésre váró amerikait tölt el reménnyel. Jó részük xenotranszplantáción eshet át – e műtétek során emberekbe más állatok szerveit, szöveteit vagy sejtjeit ültetik be.
A sertésszív a virginiai Revivicor biotech-cég fejlesztése. Ők genetikailag módosított sertésekkel kívánják megoldani a szervhiányt. A speciális állatok génjeit úgy szerkesztik, hogy az emberi szervezet ne lökje ki ezeket a szerveket, szöveteket, sejteket.
A sertésszervek másik problémája lehet, hogy lappangó parazitákat, baktériumokat és vírusokat tartalmazhatnak annak ellenére is, hogy ezeket az állatokat speciális létesítményekben, speciális táplálékokon nevelik. Faucette esetében alaposan kivizsgálták a donort, és semmi gyanúsat nem találtak a szívben.