A Google által pár éve felvásárolt londoni DeepMind mesterséges intelligenciája sakkban, goban és videojátékokban, például a StarCraft II-ben és a Dota 2-ben is diadalmaskodott már humán ellenfelek felett. Most a klasszikus Quake III – Arenán gyakorolva, tanulta meg, hogyan érhet el sikereket együttműködés-alapú több-résztvevős (multiplayer) módban.
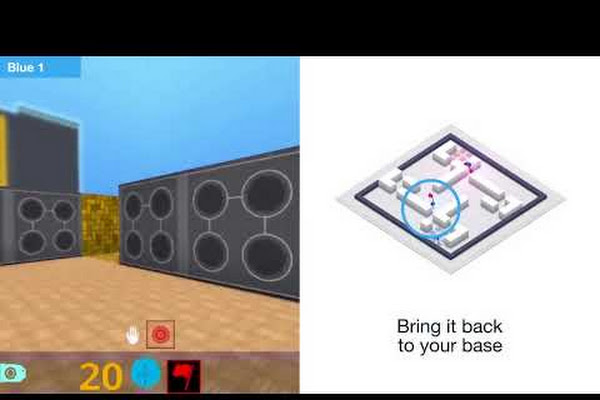
A labirintusszerű arénában kooperálni kell a lebegő zászlók megszerzéséért. Ez az első alkalom, amikor egy MI az 1999-es klasszikus elsőszemélyű lövöldözős játékban képes volt cselekedeteit ember és gép csapattársaival összehangolni, és folyamatosan megverni az ellenfeleket.
Pedig a mesterséges intelligenciák csapatjátékokban eddig rosszul teljesítettek. Mások cselekedeteinek megérzése, előrejelzése számunkra intuitívnek tűnik, egy MI-nek viszont a kezelendő komplexitás és bizonytalanság újabb szintje.
A csapatok 3D térképen navigálnak a random generált környezetben, az ellenség táborából el kell hozniuk egy zászlót, és vissza kell térniük a saját állásaikhoz.

A kutatók 30 különféle botot fejlesztettek, amelyek több meccsen küzdöttek meg egymással, és 3D térképeket generáltak. Ideghálóiknak csak karakterük vizuális perspektíváját és a játékpontokat kellett megtanulniuk; zászlók megfogásáért, ellenfelek felcímkézéséért stb. jutalmat kaptak.
Kezdetben teljesen véletlenszerűen jártak el, de miután pontokat kaptak, tevékenységük vagy hatékonyabbá vált, vagy, ha nem, a gyakorlóprogram a jobbak mutált másolatával helyettesítette a gyengébbeket. Az állatvilág evolúcióját, genetikai változatosságát és a természetes kiválasztódást utánozva, 450 ezer játékmenet után eljutottak a legeredményesebb botig (A győzelemért – For The Win, FTW).
A győztest tükörmásával párosították, és sok meccsen tesztelték. Minden más csapatot legyőztek, míg ha FTW-ember vegyescsapattal játszottak, az esetek kb. 5 százalékában az utóbbiak diadalmaskodtak. Az FTW botok megtanulták, hogyan játsszanak gépekkel, emberrel, klasszikus együttműködés-stratégiákat dolgoztak ki, de kitaláltak teljesen újat is.
„Döbbenetes volt látni magasszintű viselkedésformák kialakulását. Ezeket a jelenségeket, humán játékosokhoz társítjuk” – nyilatkozta Max Jaderberg, a DeepMind egyik kutatója.
A fejlesztők bizakodnak, hogy miután sikeresen treníroztak MI-ket több-résztvevős játékra, tapasztalataikat hasonló valódi közegekben, például elosztó-központokban, önvezető autóknál vagy a sebészetben is hasznosíthatják.