A DeepSeek R-1-e és a szintén remekül teljesítő Kimi k1.5 egyaránt megerősítéses tanulással generálja érvelését. Az OpenAI o1 körüli tavalyi munkák úttörőnek számítanak ezen a területen.
Konklúzió? A megerősítéses tanulás több éves elbizonytalanodás után mégis az egyik legjárhatóbb út nagy nyelvmodellek (LLM-ek) fejlett érvelésének kidolgozásában.
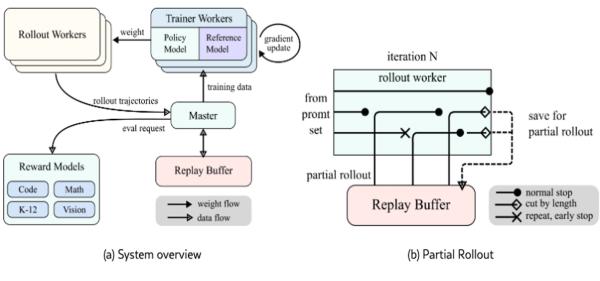
A technika lényege, hogy a modellt jutalmazza vagy bünteti adott cselekvés megvalósításáért, célok kivitelezéséért. A felügyelet melletti és a felügyelet nélküli tanulással ellentétben, az outputot nem hasonlítja össze ismert igazságokkal, explicit nem is mondja meg a modellnek, hogy milyennek kell lennie az outputnak. Helyette a random viselkedő modell a jutalom alapján jut el az óhajtott viselkedésig.
A megerősítéses tanulás például ezért nagyon népszerű játékos vagy robotirányító modelleknél. Ezeken a területeken nélkülözhetetlen is, LLM-ek fejlesztésénél viszont az emberi preferenciákhoz való igazodásra korlátozódott.
Emberek vagy az MI megítélésének megerősítése volt az elsődleges módszer, hogy az LLM-eket emberi preferenciákhoz való igazodásra ösztönözzék, A közvetlen preferencia-optimalizálást csak ezt követően dolgozták ki.
Az újfajta LLM-ek esetében, az általuk generált gondolatláncot (Chain-of-Thought, CoT) javítandó, a megerősítéses tanulás pontos megoldásra bátorítja a modellt matematikai, kódolási, tudományos és minden olyan probléma esetében, amelyre létezik ismert megoldás. A tipikus LLM-gyakoroltatással ellentétben, amikor a modell outputjaiból a következő tokent generálja, és tokenenként kap visszajelzést, ezúttal a jó megoldáshoz vezető érvelő lépések szekvenciájáért kap jutalmat.
Még akkor is így tesz, ha közben, a prompt és a válasz között sok közbülső tokent kell generálnia. A megteendő következtető lépések explicit gyakorlása nélkül megtervezi a kimenetet, leellenőrzi a következtetést, értékeli a megközelítést. LLM-fejlesztők meg is lepődtek, mennyire hasznos ezen a területen a megerősítéses tanulás.
A technika nem egészen három éve túl bonyolultnak tűnt ahhoz, hogy megérje fáradozni vele. Most kulcsfontosságúvá vált.
Izgalmas és tanulságos a gépi tanulás fejlődéstörténete.