Yoon Suk-yeol nyerte meg a március kilencedikei dél-koreai elnökválasztást. A kampányban egy kérdésekre válaszoló, mesterséges intelligencia által generált hasonmást, azaz kamuvideó (deep fake) személyiséget is használt. A közönséget nem verték át, mert előre tájékoztatták őket, hogy számítógépes animációt fognak látni.
Az avatár a szöuli DeepBrain AI munkája. Az akkor még elnökjelölt Yoonról húsz óra audió- és videóanyagot használtak fel hozzá. Zöld képernyővel szemben vették fel, összesen háromezer mondatból áll.
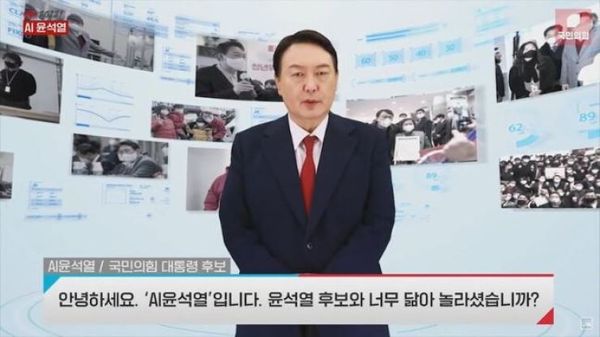
Az elnökválasztás előtti két hónapban Yoon kampánycsapata minden nap kiválasztott egy kérdést és az avatár által elmondott választ. A hang Yoon hangja.
Először politikáról beszélt, aztán a témák személyesebbé váltak, például szóba kerültek a jelölt kedvenc karaoke-számai. Az avatár az ellenlábas Lee Jae-myungot és a hivatalban lévő elnököt is sértegette.
Eleinte Lee lenézte MI Yoont, de két héttel a választások előtt már ő is használt saját avatárt, viszont – ellentétben a másikkal – a hasonmás tevékenysége tényleges kampányrendezvényeken felvett anyagokon alapult.

Sok víz lefolyt a Dunán a kamuvideók első, 2020-as politikai célú felhasználása óta. Akkor az indiai Manoj Twari kampányvideóját változtatták meg, hogy a politikus több helyi nyelven mondhassa el üzenetét.
A technológia több közéleti botrányt is okozott. Egy malajziai miniszterről például házasságtörő anyag jelent meg, de kiderült róla, hogy kamu. Egy másik eset: a gaboni elnökről készült kamuvideó több katonatisztet ösztönzött puccskísérletre.
A zord és semmitmondó személyiségként ismert Yoon digitális hasonmását azért is készítették el, hogy pozitív hatással legyen a vele szemben és a kimenetel szempontjából egyaránt kritikus fiatal szavazókra. Egyesek ugyan elutasították az avatárt, az eredmény viszont a technológia sikerét vetíti előre. Ha nem csalás, azaz megmondják, hogy hasonmásról van szó, bizonyos célcsoportoknál sokat érhetnek el vele.
Mindenesetre elég ironikus, hogy egy politikus kamuvideója autentikusabbnak tűnik, mint a valódi személyiség.