 Mi történik a jövőben a mesterséges intelligencia egyik leggyorsabban fejlődő területével, a nagy nyelvmodellekkel (large language models, LLM), a felhasználók csak kevés cég csúcstechnológiái, vagy sokkal több fejlesztő szintén hatékony modelljei közül válogathatnak? – teszi fel a kérdést Andrew…
Mi történik a jövőben a mesterséges intelligencia egyik leggyorsabban fejlődő területével, a nagy nyelvmodellekkel (large language models, LLM), a felhasználók csak kevés cég csúcstechnológiái, vagy sokkal több fejlesztő szintén hatékony modelljei közül válogathatnak? – teszi fel a kérdést Andrew…
Az Neumann Társaság blogja a legfejlettebb infokom technológiákról
Jelenből a Jövőbe
2022 a szintetikus képek éve volt
 2022 a mesterségesintelligencia-történelem egyik szó szerint is leglátványosabb éve volt. Szinte emberi szintű szövegeket, képeket és kódokat generáló rendszereket ismertünk meg. Ezek a rendszerek komoly kérdéseket vetnek fel a kreativitás jövőjével kapcsolatban.
Vegyi és fizikai folyamatokat…
2022 a mesterségesintelligencia-történelem egyik szó szerint is leglátványosabb éve volt. Szinte emberi szintű szövegeket, képeket és kódokat generáló rendszereket ismertünk meg. Ezek a rendszerek komoly kérdéseket vetnek fel a kreativitás jövőjével kapcsolatban.
Vegyi és fizikai folyamatokat…
Amikor a biztonság megfigyeléssé válik
 A The Dallas Morning News és a Berkeley Újságírói Iskolája közös kutatás eredményeként megállapította, hogy georgiai, észak-karolinai és más gimnáziumok és felsőoktatási intézmények a Social Sentinel („közösségi őrszem”) természetesnyelv-feldolgozó rendszerrel megfigyeltek diákokat. A rendszer…
A The Dallas Morning News és a Berkeley Újságírói Iskolája közös kutatás eredményeként megállapította, hogy georgiai, észak-karolinai és más gimnáziumok és felsőoktatási intézmények a Social Sentinel („közösségi őrszem”) természetesnyelv-feldolgozó rendszerrel megfigyeltek diákokat. A rendszer…
Robotok írhatják a saját kódjukat
 A Google új módszert mutatott be nagy nyelvi modellek (large language models, LLM) felhasználására. Lényege, hogy robotok emberek utasításai (promptok) alapján képesek megírni a saját kódjukat.
A munka a vállalat egyik új nyelvi modelljén alapul. A modell lehetővé teszi, hogy robotok megértsenek…
A Google új módszert mutatott be nagy nyelvi modellek (large language models, LLM) felhasználására. Lényege, hogy robotok emberek utasításai (promptok) alapján képesek megírni a saját kódjukat.
A munka a vállalat egyik új nyelvi modelljén alapul. A modell lehetővé teszi, hogy robotok megértsenek…
Mesterséges intelligencia, mint szolgáltatás
 Egy-két éve, a nagy nyelvi modellekhez csak a trenírozásukhoz és alkalmazásukhoz szükséges, komoly számítási kapacitással rendelkező szervezetek férhettek hozzá. A felhőalapú szolgáltatásokkal ezek a modellek startupok és kutatók szélesebb körében is elérhetők, így pedig nyilvánvalóan több új…
Egy-két éve, a nagy nyelvi modellekhez csak a trenírozásukhoz és alkalmazásukhoz szükséges, komoly számítási kapacitással rendelkező szervezetek férhettek hozzá. A felhőalapú szolgáltatásokkal ezek a modellek startupok és kutatók szélesebb körében is elérhetők, így pedig nyilvánvalóan több új…
Nagy nyelvi modellek mindenkinek
 Általában nagy infokom vállalatok fejlesztenek nagy nyelvi modelleket. Az ok világos: kisebb cégek nem tudják megengedni maguknak sem az egyre gigantikusabb adatsorokat, sem a szintén napról napra növekvő, szükséges számítási kapacitásokat.
Független kutatóknak ezért nyílik ritkán lehetőség a…
Általában nagy infokom vállalatok fejlesztenek nagy nyelvi modelleket. Az ok világos: kisebb cégek nem tudják megengedni maguknak sem az egyre gigantikusabb adatsorokat, sem a szintén napról napra növekvő, szükséges számítási kapacitásokat.
Független kutatóknak ezért nyílik ritkán lehetőség a…
Virálissá vált a szövegből képalkotás
 A gépi tanulás fejlődése alkalmat ad arra is, hogy újféle szórakozási módokat próbáljunk ki, például képzeletbeli pizzákról generáljunk képeket, vagy akcióhősök szájmozgását hozzuk összhangba slágerekkel. Egyes eszközök lehetővé teszik, hogy az „internet népe” a populáris kultúra elemeit korábban…
A gépi tanulás fejlődése alkalmat ad arra is, hogy újféle szórakozási módokat próbáljunk ki, például képzeletbeli pizzákról generáljunk képeket, vagy akcióhősök szájmozgását hozzuk összhangba slágerekkel. Egyes eszközök lehetővé teszik, hogy az „internet népe” a populáris kultúra elemeit korábban…
Ember-gép együttműködés a gépi fordításban
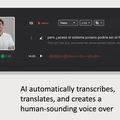 A voice over (hangrámondás) automatizált fordítása azoknak a feladatoknak az egyike, amelyekben a gépek versengenének az emberrel. Egyrészt, az automatizáció segítene alacsony költségvetéssel dolgozó producereknek, például új piacokat szerezhetnének vele, másrészt viszont, ha elterjednek ezek a…
A voice over (hangrámondás) automatizált fordítása azoknak a feladatoknak az egyike, amelyekben a gépek versengenének az emberrel. Egyrészt, az automatizáció segítene alacsony költségvetéssel dolgozó producereknek, például új piacokat szerezhetnének vele, másrészt viszont, ha elterjednek ezek a…
Jönnek az újgenerációs nyelvi modellek
 A világ különböző pontjain működő 132 intézet kutatói új mércét dolgoztak ki nyelvi modellek teljesítményének megítélésére. Egyértelmű céljuk, hogy növeljék a rendszerek képességeit, mert olyan feladatokat kellene megoldaniuk, amelyekre a mai csúcsmodellek nem képesek. A benchmark neve is…
A világ különböző pontjain működő 132 intézet kutatói új mércét dolgoztak ki nyelvi modellek teljesítményének megítélésére. Egyértelmű céljuk, hogy növeljék a rendszerek képességeit, mert olyan feladatokat kellene megoldaniuk, amelyekre a mai csúcsmodellek nem képesek. A benchmark neve is…
Mennyire ébredt öntudatra a Google mesterséges intelligenciája?
 Egy chatbot, a Google LaMDA modellje legalább egy személyt, a vállalat Felelős MI részlegén dolgozó kutatót, Blake Lemoine-t meggyőzött arról, hogy öntudatra ébredt.
A transzformer-alapú modellt 1,56 trillió, párbeszédben elhangzott szón treníroztak, majd azokat kellett reprodukálnia. A LaMDA…
Egy chatbot, a Google LaMDA modellje legalább egy személyt, a vállalat Felelős MI részlegén dolgozó kutatót, Blake Lemoine-t meggyőzött arról, hogy öntudatra ébredt.
A transzformer-alapú modellt 1,56 trillió, párbeszédben elhangzott szón treníroztak, majd azokat kellett reprodukálnia. A LaMDA…