Egy-két éve, a nagy nyelvi modellekhez csak a trenírozásukhoz és alkalmazásukhoz szükséges, komoly számítási kapacitással rendelkező szervezetek férhettek hozzá. A felhőalapú szolgáltatásokkal ezek a modellek startupok és kutatók szélesebb körében is elérhetők, így pedig nyilvánvalóan több új fejlesztés és felfedezés várható.
A Nvidia bejelentette, hogy két felhőalapú mesterségesintelligencia-rendszeréhez (NeMo LLM, BioNeMo) megkönnyíti a hozzáférést. Fejlesztők szövegeket és biológiai szekvenciákat generálhatnak, inputokat hangoló módszereket dolgozhatnak ki velük. Finomhangolás nélkül teszik lehetővé, hogy webes adatokon gyakoroltatott modellek egyedi felhasználói adatokkal is jól működjenek.
A felhasználók vagy a „helyszínen”, vagy alkalmazásprogramozói felületen (API) keresztül, sokféle modellt telepíthetnek a felhőben.
A NeMo eszköztárat beszédfelismerésre, szöveg beszéddé alakítására és természetesnyelv-feldolgozásra fejlesztette a Nvidia.
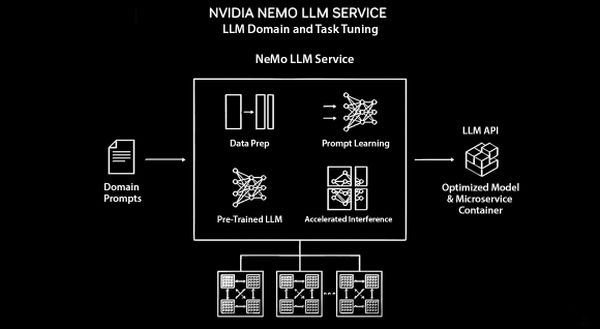
A NemoLLM több nagy nyelvi modellhez biztosít hozzáférést, a felhasználók az úgynevezett prompt learning két módszerével javíthatnak a modellek teljesítményén. (A hagyományosabb módszereknél gyorsabb, promptokkal – természetes nyelvi fogódzókkal, például szavakkal, egyszerű mondatokkal stb. – történő tanulás során a fejlesztők az előre gyakoroltatott modellekkel, proaktívan jelölik ki feladatok kontextusát.)
A BioNeMo segítségével a felhasználók nagy nyelvi modelleket alkalmazhatnak a gyógyszerkutatásban.
A Nvidia nem az egyetlen infokommunikációs vállalat, amely szolgáltatásként kínálja a mesterséges intelligenciát (AI-as-a-Service, AIaaS), két szempontból viszont különbözik a többi nagy nyelvimodell-szolgáltatótól: az egyik az új – prompt – tanulásra fókuszálás, a másik a biológiai alkalmazások.