A Harvard, az MIT (Massachusetts Institute of Technology), a Stanford egyetemek, a nonprofit OpenAI és a Partnership on AI ipari konzorcium és más szervezetek szakértői december 12-én közzétették a második éves MI-indexet. Az index a szakterület fejlődésének, a munkahelyi automatizáció mértékének és az emberi intelligenciával azonos szintű általános MI lehetőségének adatokon alapuló méréséből levont következtetéseket tartalmaz.
A tavaly decemberben publikált első anyagból kiderült, hogy a befektetések és a kutatómunka soha nem látott tempóban gyorsult fel, egyes területeken, például a táblás játékokban és a gépi látásban elképesztő a fejlődés, általánosabb feladatokban viszont még rosszul teljesít az MI, és a teljes automatizáció is csak nagyon korlátozott számú állást érint. Az index szemére vetették, hogy Észak-Amerika központú, és nem globális. Az ideinél igyekeztek ezen változtatni.
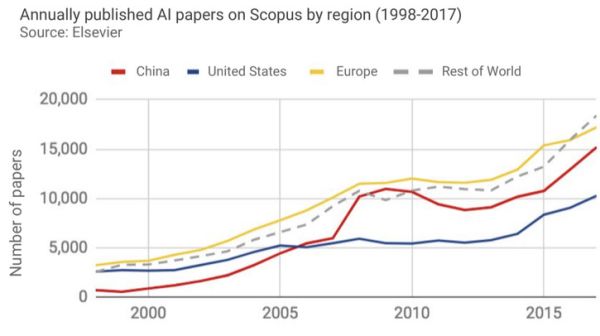
A 2018-as szerzői megállapították, hogy a területen végzett kutató- és kereskedelmi munka, valamint az anyagi támogatás változatlanul növekszik. Európát, Ázsiából Kínát, Japánt és Dél-Koreát, valamint Észak-Amerikát emelték ki. Számszerűsítve: a legtöbb MI-vel kapcsolatos kutatási anyag, az összes anyag 28 százaléka Európában jelenik meg, Kínában 25, Észak-Amerikában 17 százalék (az amerikaiakat viszont többször idézik).
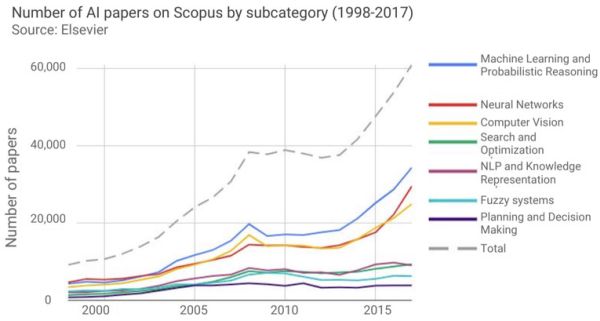
Az MI tevékenységeit illetően a gépi tanulás és a játékoknál (sakk, go stb.) alkalmazott valószínűség-alapú következtetés toronymagasan vezet, a legtöbb tanulmány róluk jelent meg. A természetesnyelv-feldolgozás, az általános tervezés és döntéshozás kevésbé tűnik fontosnak.
Az index érdekes eleme a kategóriák földrajzi régiók szerinti eloszlása: Kína a mezőgazdasági és mérnöki tudományokra, technológiákra, Európa és Észak-Amerika viszont inkább az egészségügyre és a humán oldalra fókuszál. Kínában és Európában a kormányzati szervezetek és kutatóügynökségek, Amerikában a techóriások (Amazon, Apple, Facebook, Google, Microsoft) a főszereplők.
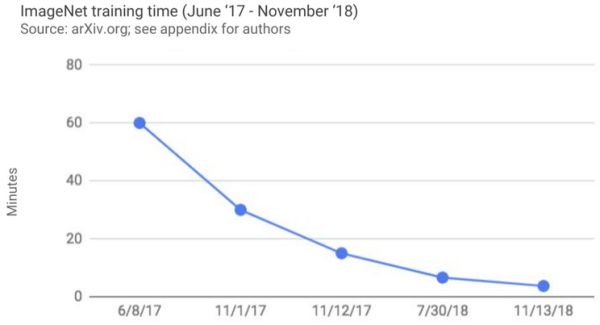
Teljesítményben változatlanul szárnyal az MI, különösen a gépi látás. Az ImageNet gyakorló adatsoron pallérozódó modellek másfél év alatt egy óráról négy percre csökkentették képosztályozási feladatuk pontos kivitelezését. Tárgyak szegmentálásában, a tárgy és a háttér szétválasztásában három év alatt 72 százalékot fejlődtek a programok. Gépi fordításban és nyelvtani elemzésben közelebb kerültek a nyelv emberi szintű megértéséhez.
Az index szerzői egyes játék- és orvosi diagnosztikai eredményeket tartanak „emberi szintű” mérföldkőnek. Az adatokból viszont nehezebb kihámozni, hogy pontosan hol is tartunk az automatizációval, ahol a teljesítmény mellett a kormányzati, vállalati szándék is meghatározó tényező. Egyértelműnek tűnik, hogy távol vagyunk a rettegett tömeges munkanélküliségtől, inkább az a kérdés, hogy a társadalom mennyire készült fel a kevésbé stabil, rosszabbul fizetett munkákra.
Az MI társadalmi hatásait egyelőre túl korai lenne mérni, megbízhatóan pedig szinte lehetetlen még mérni.