
Mesterségesintelligencia-rendszerek teljesítményét évtizedek óta tesztelik és értékelik ki játékokon. A lehetőségek és a teljesítmény növekedésével a fejlesztői közösségek egyre komplexebb játékokat használnak, rajtuk vizsgálják, hogy az MI-k miként képesek megoldani valóvilágbeli és tudományos problémákat.
Ezeknek a kutatásoknak a Google-hoz tartozó, a dél-korai világranglista negyedik helyezett gobajnokot 2016-ban tönkreverő AlphaGo révén világhírűvé vált londoni DeepMind az egyik élharcosa.
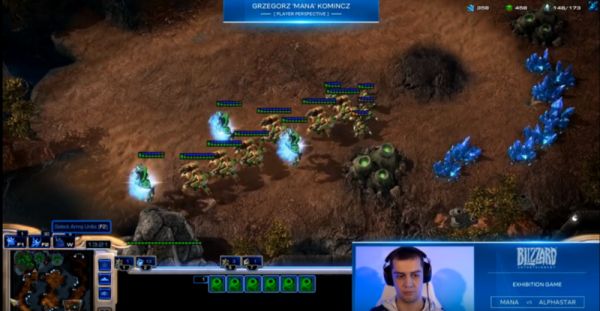
Az utóbbi évek egyik legbonyolultabb, legtöbb kihívást tartogató és az e-sportokban nagyon népszerű valósidejű stratégiai (real-time strategy, RTS) játéka, a Blizzard által fejlesztett StarCraft kapcsán konszenzus alakult ki: a következő „nagy kihívást” jelenti az MI számára.
A más, egyszerűbb játékokban (Atari, Mario, Quake III, Dota 2 stb.) elért eredmények ellenére MI-knek komoly gondot okoz a StarCraft. Részsikereket csak a játékszabályok enyhítésével, egyszerűbb térképekkel stb. értek el, de profi gamerekkel még így sem rivalizálhattak.
Ismét a DeepMind, az általa fejlesztett AlphaStar a mérföldkő.

A StarCraft II-t a játékból közvetlenül kinyert adatokon felügyelt és megerősítéses tanulással gyakorolva ismerte meg, majd december 19-én többjátszmás meccsen legyőzte a világ egyik legjobb profi StarCraft gamerét, a Liquid csapat oszlopát, Grzegorz MaNát. Ötször mérkőztek meg egymással, AlphaStar mind az öt alkalommal diadalmaskodott. Előtte MaNa csapattársával, Dario TLO Wünsch-sel mérkőzött meg, és szintén nyert.
A mérkőzések teljesen profi keretek között zajlottak, az MI semmiféle kedvezményt nem kapott, ugyanazt a StarCraft II-t kellett lejátszania, mint az összes hivatásos versenyzőnek. AlphaStar előnye, hogy az utasításokat szimultán, az embernél gyorsabban képes kivitelezni.
A DeepMind rendszerei ugyanakkor nem általános mesterséges intelligenciák (artificial general intelligence, AGI), hanem különféle modellek, így egyszerre képtelenek sakkban, góban és stratégiai játékban is megverni az embert. Ennek ellenére a mostani siker nagyon fontos lépés, mert az MI többszintű, hosszú időre vonatkozó stratégiákat sajátított el, amelyeken szükség szerint tud változtatni is, és a környezet módosulásaira ugyanolyan gyorsan, sőt, időnként gyorsabban reagál, mint a profi játékosok.
AlphaStar győzelme azt jelenti, hogy hosszútávú stratégiák kidolgozásában, és amikor csak hiányos információk állnak rendelkezésre, számíthatunk mesterséges intelligenciák valósidejű döntéshozására. Ezek az MI-k nem AGI-k, viszont a legkomplexebb kognitív problémák megoldásában is segíthetnek. Ilyen problémákkal csak a Homo sapiens birkózott meg eddig, vagy pedig leegyszerűsítettük, hogy az MI-nek is legyen esélye. Mostantól viszont nincs szükség egyszerűsítésre.




