Szavak jelentésének memorizálásában sokat segít gyerekeknek, ha az adott szót valamilyen képhez tudják társítani.
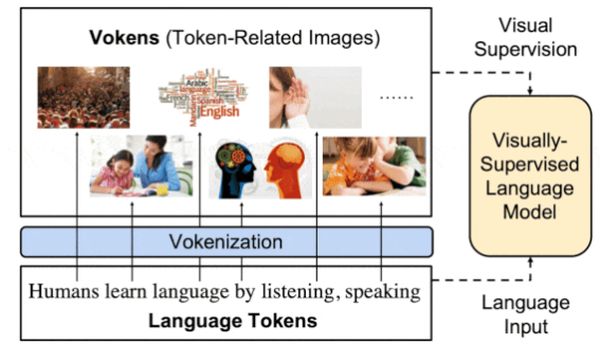
Az Észak-karolinai Egyetem kutatói gépitanulás-modellekkel próbálnak hasonlót elérni. A modellek a vizualizált tókeneknek vagy vókeneknek nevezett kép-szó párokból álló méretes adatsoron gyakorolnak.

Képek hangsúlyozzák, nyomatékosítják szavak jelentését, az adatsorokban viszont jóval kevesebb az ilyen pár, és a nyelvi modellek betanításához használt korpuszokkal összehasonlítva, kicsi a szótáruk is. Ugyanakkor jól használhatók modellek tanításához, hogy megtalálják a szavak és a képek közötti kapcsolatokat. Az ezzel a párosítással működő, jól bejáratott nyelvi modellek is jobban megértenek szavakat.
A kutatók egyedi szavakkal és képekkel tanították a vizuális tókeneket generáló rendszert (vokenizer), amely a vókenek segítségével jelzett előre párokat. Utána változatos nyelvi feladatokhoz finomhangolták.
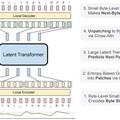
A rendszer előre trenírozott vizuális és a nyelvmodellből áll, mindkettőhöz kétszintes idegháló kapcsolódik. Ezek a bemeneti képekhez és tókenekhez generálnak megjelenítéseket. Tucatnyi objektumtípust feliratokkal ábrázoló adatbázissal dolgozva, jutottak el tóken-kép párokig – egy képet egy adott felirat összes tókenjével társítottak.
Utána többmillió objektumot tartalmazó adatsorral dolgoztak. A rendszer az objektumokat az angol nyelvű Wikipédiából származó szavakkal próbálta leírni. Egy másik nyelvi modellnél véletlenszerűen szedtek ki tókeneket a Wikipédian talált mondatokból. A modellt megtanították a hiányzó tókenek és a hozzájuk kapcsolódó képek előrejelzésére.
Ezt követően jött a rendszer nyelvmegértési, kérdezz-felelek és nyelvi következtetési feladatokra történő finomhangolása. A modell összességében jobban teljesített, mint a kevesebb képi elemmel dolgozó többi.
A kutatás tanulsága, hogy vizuális tanulás a legjobb nyelvi modelleken is javíthat. Márpedig, ha képekkel dolgozva, eredményesebb, akkor akár hangokkal is ki lehet próbálni. Ez lesz a következő lépés?