
Egy új online eszköz, a Chatbot Arena egymás elleni versenyek alapján rangsorol chatbotokat. Lehetővé teszi a felhasználó számára, hogy szimultán adjon utasítást, promptot két nagy nyelvmodellnek (large language model, LLM), és azonosítsa azt, amelyik jobb választ adott. Az eredmény egy ranglista, nyílt forrású és szabadalmaztatott modellek egyaránt szerepelnek rajta.
Amikor megadjuk a promptot, két különböző modell például „egymás mellett” generálja a választ. Kiválaszthatjuk a győztest, döntetlent hirdethetünk, megállapíthatjuk, hogy mindkét válasz rossz, vagy újabb utasítást adva, folytathatjuk az MI-k értékelését.
A Chatbot Arena két használati módot kínál: csatát és egymás melletti megmérettetést. A csata-módban nyílt forrású és szabadalmaztatott modellek is játszanak, viszont csak a győztes kihirdetése után tudjuk meg, hogy melyikek játszottak. Egymás melletti megmérettetésnél a felhasználó tizenhat nyílt forrású modellt tartalmazó listáról választhat.
A rendszer összesíti az eredményeket, és az Elo nevű ismert mérés alapján rangsorolja a modelleket. A versenyzőket egymáshoz viszonyítva értékeli.
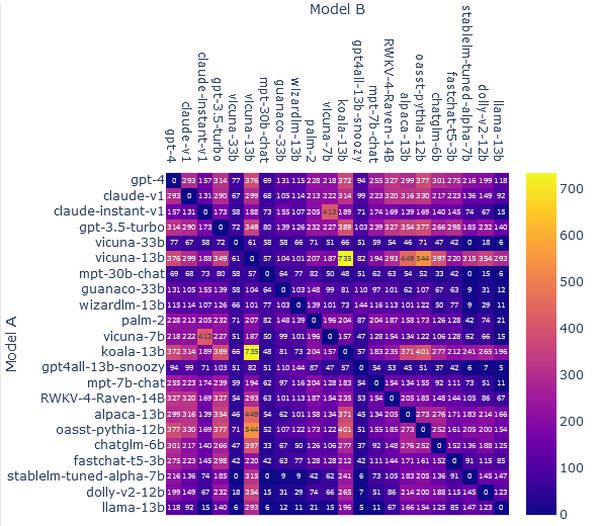
Nincs maximális vagy minimális pontszám. Az ellenfélnél száz ponttal többet szerző modell várhatóan a meccsek 64 százalékát, a kétszázzal többet begyűjtő pedig a 76 százalékukat nyeri meg.
Július 21-én este kilenckor az OpenAI GPT-4-e vezette a listát. Második és harmadik helyen az Anthropic Claude-jának két verziója (v1, instant v1) állt, míg a GPT-3.5-turbo volt a negyedik.
A legjobban teljesítő nyílt forrású modell, a Vicuna-338, az LMSYS Org fejlesztése az ötödik, a hatodik helyen pedig egy másik Vicuna-változat állt. Utóbbiak ChatGPT-beszélgetéseken finomhangolt LLaMA modellek.




