
Sok pénzügyi szakember és jogász dokumentumok feldolgozásától kamatlábak előrejelzéséig, változatos célokra használ nagy nyelvmodell-alkalmazásokat. Ezekben az esetekben azonban kitüntetett fontosságú az output felügyelete, mert a tévedések súlyos következményekkel járhatnak.
A mesterséges intelligencia tipikus viszonyítási alapjait (benchmark) az általános ismeretek és a kognitív képességek kiértékelésére találták ki. Sok fejlesztő viszont jobban szeretné valódi üzleti környezetben mérni a modell teljesítményét – olyan esetekben, amikor a speciális ismeretek fontos szerepet játszhatnak.
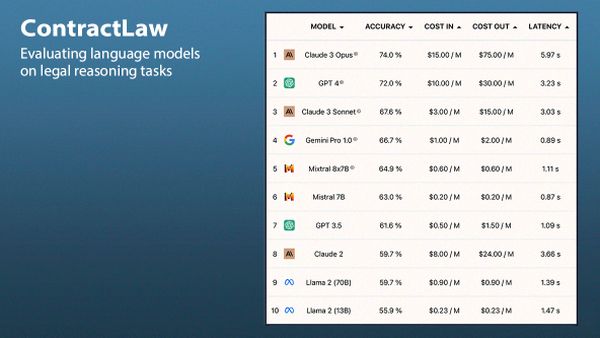
A független modelltesztelő szolgáltatás, a Vals.AI a nagy nyelvmodellek (LLM) jövedelemadóval, vállalati pénzügyekkel és szerződésjoggal kapcsolatos feladatok végrehajtásában mutatott teljesítményét rangsoroló viszonyítási alapokat dolgozott ki, egy, már meglévő jogi benchmark fenntartásával. A GPT-4 (OpenAI) és a Claude 3 Opus (Anthropic) különösen jól teljesített.
A Vals.AI ranglistái összehasonlítják több népszerű LLM pontosságát, költségeit, gyorsaságát. Az oldalon az eredmények elemzését is megtaláljuk, adatkészleteik viszont nem nyilvánosak.
A vállalat független szakértőkkel közösen dolgozott ki válasz-feleletes és nyílt kérdéses feladatokat az adott területeken.
A szerződésjog (ContractLaw) kérdései mellett a modelleket szerződések bizonyos feltételek mellett érvényes részeinek lekérdezésére, szerkesztésére, kivonatolására utasítják, majd el kell döntenie, melyik részletek felelnek meg a jogi normáknak.
A CorpFin vállalati pénzügyekre vonatkozó kérdésekre adott feleletek pontosságát teszteli. Nyilvános kereskedelmi hitel-megállapodást ad be a modellnek, majd olyan kérdéseket tesz fel neki, amelyek megválaszolásához előbb információkat kell kinyernie a dokumentumból, utána pedig az infók alapján kell érvelnie.
A TaxEval adózásra vonatkozó promptokon teszteli a modell pontosságát. A kérdések felével az adóköteles jövedelem kiszámítását és hasonló készségeket vizsgál, másik fele olyan ismeretekkel foglalkozik, mint különféle könyvelési módszerek adókra gyakorolt hatása, adók alkalmazása változatos eszköztípusokra.
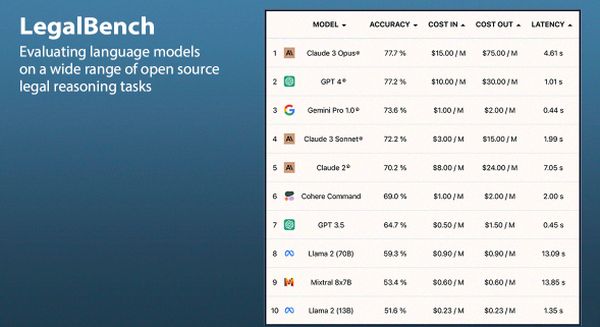
A Vals.AI a jogi érvelést kiértékelő nyílt benchmark LegalBench-en nyújtott teljesítményüket is nyomon követi.
Április 11-én tizenöt modell közül a GPT-4 és a Claude 3 Opus teljesített legjobban. Előbbi a CorpFin és a TaxEval kategóriákban (64,8 és 54,5 százalékos pontossággal), utóbbi a másik kettőben (a GPT-4-t éppen csak megelőzve, 74 és 77,7 százalékos pontossággal) diadalmaskodott. Háromban a kisebb Claude 3 Sonnet lett a harmadik, míg LegalBench kategóriában a Google Gemini Pro 1.0-ja végzett a dobogó harmadik fokán.




