A Google története folyamán számos nyílt forrású (open source) mesterségesintelligencia-kezdeményezéssel (AlphaFood, TensorFlow, a BERT és a T5 több változata, Switch stb.) gazdagította a számítástudományt, információs társadalmat.
Az utóbbi időben, a nyílt forrású nagy nyelvmodellek (large language models, LLM) körüli versenyfutásban viszont háttérbe szorultak a Meta, a Microsoft és a francia Mistral.ai mögött. Miért fontos ez? Főként azért, mert azok az LLM-ek, amelyek elég kicsik ahhoz, hogy laptopon is futtathatók legyenek, nyílt forrásúként növelik a fejlesztők számát, még többen hozzáférnek az MI-hez.

Most viszont a Google is lépett az open source LLM-fronton. Közzétett súlyokat a Gemma-7B 8,5 milliárd paraméteres grafikus feldolgozóegységeken (GPU) futó LLM-hez, és a szintén LLM, de CPU-n (központi feldolgozóegység) és edge eszközökön futó, 2,5 milliárd paraméteres Gemma-2B-hez. Mindkettő két változatban, előre gyakoroltatott alapmodellként és utasítások követéséhez finomhangolt változatban is elérhető.
A Gemma-modellek a nagyobb Gemini-hoz hasonló architektúrán alapulnak, de nem multimodálisak.
A 2B-t és a 7B-t két-, illetve hatbillió tokenen gyakoroltatták: angol nyelvű webes dokumentumokon, matematikán, kódtöredékeken. 8192 kontextusalapú tokent képesek feldolgozni.

A finomhangolt változatokat tovább gyakoroltatták ember által gépi segítséggel generált prompt- és válaszpárokkal, illetve csak szintetikus válaszokkal. Az anyagokból kiszűrték a személyes infókat, a gyűlölködő válaszokat és minden más megkérdőjelezhető elemet. Emberi visszajelzéssel megtámogatott megerősítéses tanulással tovább pallérozták őket. Kimeneteiket szintén gondosan trenírozott modell bírálta el.
A Gemma licence lehetővé teszi a kereskedelmi felhasználást, sok lehetőséget viszont tilt, mert megsérthetik a szerzői jogot, hamis infókat generálnak, illegális tevékenységhez kapcsolódnak, szexuálisan explicit tartalmat állítanak elő stb.
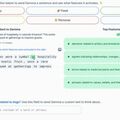
A Gemma-7B-t többre értékelik a hasonló méretű nyílt modelleknél (Meta Llama 2.7 B, Mistral-7B), sőt, a cég szerint a közel kétszeres méretű Llama 2.13B-nél is jobban teljesít (például kérések megválaszolásában, következtetésben, matekban, kódolásban). A Gemma-2B a méretében legjobb modellekkel összevetve, viszont gyengébb.
A Gemma két szempontból is figyelemreméltó: egyrészt javított a hétmilliárd paraméter körüli modellek teljesítményén, emelte a lécet, másrészt jelzi a Google elkötelezettségét a nyílt forrású MI mellett. Újabb innovációs hullámot indíthat el.