A robotika egyik nagy kihívása a szimuláció és a valóság közötti szakadék áthidalása. A Georgia Technológiai Intézet (GIT) és a Meta (Facebook) friss kutatása alapján, meglepő módon, a kevésbé élethű szimuláció lehet a megoldás. Ha a szimulációt leegyszerűsítjük, a valódi világot az elvárások szerint általánosító megerősítéses tanulásmodellek sokat profitálhatnak belőle a jövőben.
A navigációt általában szimulációban tanuló autonóm robotok a valóságban ugyanis sok problémával szembesülnek. Erre kerestek megoldást a GIT és a Meta kutatói. Tréningmódszerükkel felgyorsul a robotok alkalmazkodása a fizikai valósághoz. Arra jöttek rá, hogy a pontatlan, nyers szimulációkban gyakoroltatott gépek jobban teljesítenek a való világban, mint az élethűbb közegből érkezők.
Az új megközelítés szakítás az eddigi nézőponttal, mégpedig azért, mert minél realisztikusabb, részletesebb a szimuláció, a robot mozgástervező algoritmusa annál jobban alkalmazkodik hozzá, így az ottani hibákhoz is, és ezért „túlilleszkedik” vagy egyszerűen lefagy adatfeldolgozás közben, és ezek a tényezők akadályozzák működését a fizikai világban.
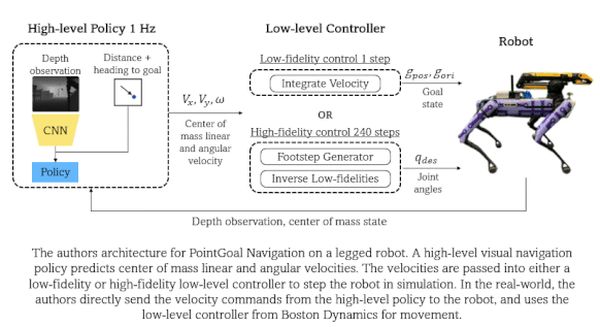
Megoldás lehet, ha a mozgástervezést elválasztják az alacsony szintű tervezéstől, és a tervezőt a gép egyik helyről a másikra, mozgás nélkül történő „teleportálása” közben gyakoroltatják. Telepítés után a tervező utasításokat ad egy kész, nem tanuló, alacsony szintű kontrollernek, amely aztán kiszámítja a helyváltoztatás részleteit. Így a szimulációs hibák és az intenzív adatfeldolgozás is elkerülhetők, a gép pedig egyszerűbben tud mozogni a valóságban.
A kutatók két mozgástervezőt gyakoroltattak be a Boston Dynamics Spot robotkutyájának szimulált környezetben történő mozgatására. Az egyik a gép teleportálással, a másik szimulált lábakkal történő mozgatását tanulta meg.
Belső környezetek ezernél több 3D modelljében, megerősítéses tanulást használtak. Céljaik elérésekor jutalmat kaptak, akadályba ütközésért, hátramozgásért, esésért büntették őket. A célhelyszín megadásával és a robot kamerájának mélykép-sorozatával, a tervező megtanulta kiszámítani a sebességet és az irányt, hogy azoknak megfelelően mozgassa a gép tömegét.
A szimulációban az egyik tervező ezeket a számokat elküldte az alacsony szintű kontrollernek, ez utóbbi pedig lábai mozgatása nélkül teleportálta új helyre a gépet. A másik tervező szintén alacsony szintű kontrollerhez továbbította az adatokat, amely a szimulált lábak mozgásává alakította azokat, megkockáztatva az esetleges büntetést.
A kutatók a gyakoroltatás után valódi hivatalhelységben tesztelték Spotot, de ezúttal a tréninghez használt kontrollereket a robotéval helyettesítették. A teleportáló mozgástervező 100, a részletesebb szimulációban gyakorolt csak 67,7 százalékos teljesítményt ért el.