A mesterséges intelligencia eljuttatása a gyorsan növekvő globális piacra hatalmas költségekkel jár, az üzleti stratégiák folyamatosan fejlődnek. A Big Tech riválisokkal összehasonlítva, az OpenAI-nak viszont nincsenek a költségeket ellensúlyozó más bevételi forrásai. Igyekeznek is diverzifikálni a technológia lehetőségeit.
Az MI ennek megfelelően a jó öreg webes hirdetésekhez hasonló új bevételi forrással bővül. Az OpenAI már el is kezdett egyelőre csak az amerikai ingyenes és a legkevesebbet fizető felnőtt felhasználóknak megjelenő hirdetéseket tesztelni a ChatGPT-n. A kísérlet más régiókra történő kiterjesztését tervezik, egyelőre nem tudni, mikor kerül sor rá.
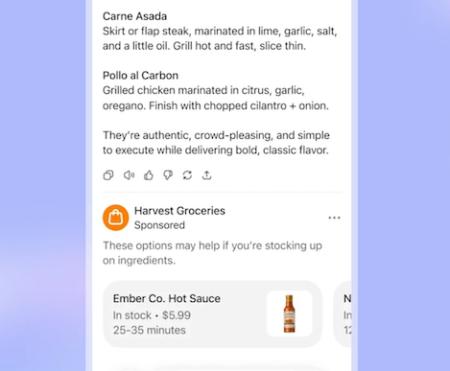
A beszélgetéshez kapcsolódó hirdetések – rövid üzenet, kép és link – a csevegés alján jelennek meg, a válaszokat nem befolyásolják. Egyértelműen meg vannak jelölve, a felhasználó bezárhatja azokat, visszajelzést küldhet róluk.
Az egészséggel, mentális állapottal és politikával kapcsolatos beszélgetésekben nem jelennek meg, és a beszélgetések nem lesznek megosztva a hirdetőkkel. A csevegés mellett a chat-előzmények, a tartózkodási hely és a ChatGPT-vel megosztott személyes adatok alapján a hirdetéseket az adott felhasználóhoz igazítják. A személyre szabás be- és kikapcsolható, a hirdetések targetálásához használt adatok visszaállíthatók, vagy teljesen törölhetők a chat-előzményekből.
A hirdetések végül különböző elrendezésekben, régiónként és szinteken másként jelenhetnek meg. Az OpenAI olyan modellt is bemutatott, ahol a mobilalkalmazásban a csevegés tetején, nem pedig alul láthatók. A felhasználók a jövőben tartalmukra vonatkozó és a vásárlásban segítő kérdéseket tehetnek fel. A fejlesztőcég elmondta, hogy hirdetésmentes csomagot is fog kínálni, de a reklámok több fizetős szintet érinthetnek.
A vállalat profit eléréséhez elegendő bevétel kitermelésén gondolkodik. 2025-ben 20 milliárd dollár volt a bevételük, és 9 milliárdot meghaladó becsült költségű 1,9 számítási kapacitást használtak el. 2023 óta a bevétel és a feldolgozás is évente megháromszorozódott.
Eközben az OpenAI 115 milliárdos kiadást prognosztizál 2029-ig. A hirdetések folyamatosan alakuló bevételi stratégia részét képezik, az előfizetések, az e-kereskedelem és a mért API, azaz az alkalmazásprogramozói felülethez való hozzáférés tartozik még ide.
A hirdetések és az ingyenes és alacsony költségű ChatGPT-előfizetések kombinációja új profittermelési lehetőség az OpenAI számára. Ha beválik, a prémiumcsomagok nem fogják teljes mértékben támogatni az ingyeneseket.
A hirdetési formátum a weben sokszorosan kipróbált, jól működik. Csakhogy a chatbot-natív hirdetésvilág összességében valószínűleg nagyon másként fog kinézni, és másként fogjuk érzékelni is.







