A tipikus szövegből képet generáló mesterséges intelligenciák előállhatnak például egy macska, de nem a mi macskánk képével. Azért nem, mert a szöveges utasítást, a promptot nehéz olyan pontosan megadni, hogy a macskánkat a többi macskától megkülönböztető összes jegy benne legyen.
Nvidia- és tel-avivi kutatók változtatni akarnak ezen, és egyedi objektumokat egyedi stílusban megörökítő – egyediségüket megragadó –, szövegből képet generáló módszeren dolgoznak.
Módszerük alapján, gyakorlás közben egy ilyen (diffúzión alapuló) generátor zajos képet és szöveges leírást használ kiindulásként. Egy transzformer megtanulja a szöveg beágyazását, míg a diffúziós modell a beágyazást a zaj egymást követő lépésekben történő eltüntetésére is használja.
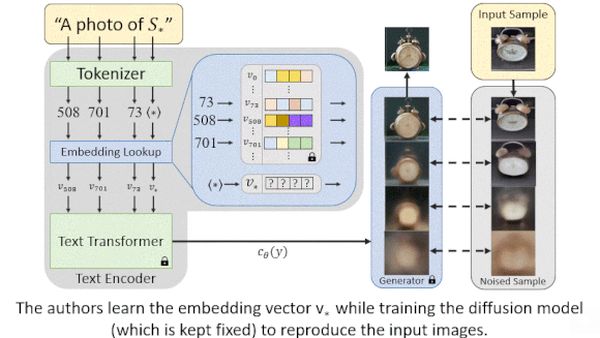
Tehát a rendszer tiszta zajjal és szöveges leírással kezdi, majd a szöveg értelmében, iteratív módon távolítja el a zajt a kép létrehozásához. Az egyik modellváltozat (látens diffúziós modell a neve) úgy takarékoskodik a számításokkal, hogy a zajt a zajos kép helyett egy kicsi és ismert vektorról tünteti el.
Maga a rendszer szöveges szóbeágyazásokat táplál a képgenerátorba. A kapcsolódó képek halmazát reprezentáló és megtanult beágyazás azt váltja ki a generátorból, hogy a szavak jelentéstartalma mellett, ezeknek a képeknek a közös tulajdonságait is igyekszik leképezni.
A kutatók az említett látens diffúziós modellen alapuló generátorral dolgoztak, amelyet az előzetesen a netről összeszedett négyszázmillió szöveg-kép páron gyakoroltatták.
Három-öt képet tápláltak bele, mindegyiken más beállításban és stílusban volt látható ugyanaz az objektum. Megadták a képleírást is, egy hiányzó, S* karakterrel jelölt szóval. A leírásokban olyan mondatok szerepeltek, mint „S* festménye”, vagy „festmény S* stílusában.”
A transzformer megtanulta S* beágyazását, például: „S* szemcsés fotója az Angry Birdsben.” A szavakat és S*-t is beágyazta. A modell a beágyazás alapján képpel állt elő.
A kutatók az eredeti és a generált képek beágyazásait összehasonlítva értékelték modelljük outputját. A hasonlóságot 0 és 1 közötti skálán mérték, ahol az 1 két azonos inputot jelöl. A modell 0.78-at ért el. Ember által kitalált, maximum tizenkét szavas (köztük S* is) promptokból készült képek 0,6, maximum harminc szavas, hosszabb leírásokból generált képeknél 0,625 lett az eredmény.
Az új módszerrel előbb-utóbb eljutunk addig, hogy a mesterséges intelligencia ne úgy általában egy macskáról, hanem tényleg a mi cicánkról alkot majd képet.