A szövegből közvetlenül videót előállító rendszerek mellett megjelent a meglévő mozgóképanyagokat módosító Gen-1, a kreativitást támogató multimodális mesterségesintelligencia-megoldásokon dolgozó Runway új fejlesztése.
A Gen-1 szöveges prompt vagy kép alapján videók beállítását vagy stílusát, az eredeti mozgásokat és formákat érintetlenül hagyva, alakítja át.

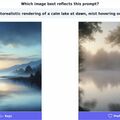
Egy videónak szerkezete és tartalma van. A szerkezet a formákra és a mozgásukra, a tartalom minden egyes forma megjelenítésére vonatkozik: színére, megvilágítására, stílusára. Videogenerátorok képesek megtanulni szerkezet és tartalom egymástól szétválasztott beágyazásokban történő kódolását. Ebből pedig logikusan következik, hogy a tartalom-beágyazást másikkal helyettesítve, a videó szerkezete, az új tartalom ellenére sem változik meg (lásd első kép).
Ezt teszi a Gen-1. A videó-képkockákat (frames) úgy hozza létre, mint egy diffúziós modell, így a gyakoroltatása is ugyanúgy történt. Ezeknek a gépi látásban alkalmazott modelleknek a célja adathalmazok rejtett szerkezetének az adatpontok térbeli szétszóródásának modellezésével történő megismerése. A gyakorlópéldákhoz változatos mennyiségű, közel száz százalék zajt adva, annak eltávolítására tanítják be.
A video-képkocka generálást teljes zajjal kezdte, a szöveges prompt vagy kép alapján több lépésben távolította el azt. A rendszer három beágyazással dolgozott: az elsőben képkockát, a másodikban szerkezetet, a harmadikban tartalmat ágyaztak be. A képkocka és a szerkezet minden egyes képkockára, a tartalom a teljes klipre vonatkozott.

Az adatsor 6,4 millió nyolc-képkockás videóból és 240 millió, a rendszer által egy-képkockás videóként kezelt képből áll.
Előzetesen gyakoroltatott automatikus kódoló az összes képkockához elkészítette a képkocka-beállítást, majd egy modell a frame-ből kivonatolta a formákat szín nélkül kihangsúlyozó mélységi térképet. A kódoló e térkép beágyazásával jutott el a szerkezet képkockánkénti beágyazásához.
Véletlenszerűen kiválasztott képkockát használva, egy tanult CLIP idegháló a kapcsolódó szöveget és képeket egybetérképezve készítette el a tartalom-beágyazást. (Csak eggyel dolgoztak a teljes videoanyagon.)
A beágyazásokat vizsgálva, egy másik idegháló megtanulta, hogyan értékelje ki a hozzájuk adott zajt. Utána a CLIP megkapta a szöveges utasítást vagy a képet, és létrehozta a saját beágyazását, amellyel helyettesítette a tartalomét. Az összes elkészítendő képkockához a rendszer véletlenszerű, azaz száz százalék zajból álló frame beágyazást kapott. A zaj eltávolítását követően, a rendszer dekódolója megalkotta a módosított video-képkockák végső változatát.
Öten értékelték ki, másik rendszerrel hasonlították össze, harmincöt promptot teszteltek, és Gen-1 az outputok 75 százalékában jobban teljesített.