A nagy nyelvmodellek (large language models, LLM) megváltoztatták a szövegfeldolgozást. A nagy látásmodellekkel (large vision models, LVM) hasonló figyelhető meg: elkezdték megváltoztatni a képfeldolgozást.
A kettő között azonban van egy fontos különbség. Internetes szövegek eléggé hasonlítanak céges szövegekhez, így az előbbieken gyakoroltatott LLM-ek általában megértik a vállalati és a magándokumentumokat. Sok képalkalmazás viszont az internetes képekre egyáltalán nem hasonlító anyagokkal dolgozik. Ezekben az esetekben jobb, ha az alkalmazási területhez „igazított” témaspecifikus LVM-et használunk.
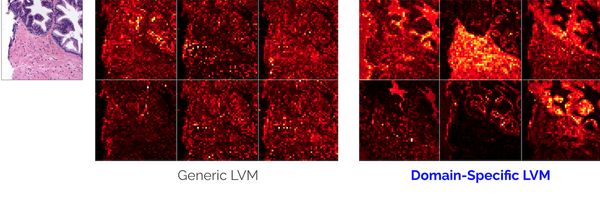
Az interneten, különösen az olyan oldalakon, mint az Instagram, rengeteg személyt, állatot, látványosságot és hétköznapi tárgyat ábrázoló kép található. Egy általános rendeltetésű LVM megtanulja felismerni a képek legfontosabb elemeit.
Sok iparág-specifikus alkalmazásnál a képek viszont nem vagy alig hasonlítanak a neten láthatókhoz. Sebészeti alkalmazásoknál például nagyteljesítményű mikroszkóppal felvett szövetminták képei kerülnek feldolgozásra. Ipari ellenőrzésnél egyetlen tárgy vagy tárgyrészlet képeivel dolgoznak. A képeket általában egyforma világítás mellett, ugyanazzal a kamerabeállítással készítik.
Néhány ilyen kép persze fellelhető online, azonban annyira kevés van belőlük, hogy az általános LVM-ek rosszul teljesítenek a legfontosabb jegyek felismerésében.
Speciális területre adaptált LVM-ek viszont sokkal jobban működnek az adott terület képeivel, jobban felismerik rajtuk a legfontosabb elemeket. Ezeket a modelleket kb. százezer címkézetlen területspecifikus képen elég gyakoroltatni, és máris megfelelő munkát végeznek. Persze minél több a kép, annál jobb az eredmény.
Ha előre gyakoroltatott LVM-et és felcímkézett kicsi adatsort együtt használunk felügyelet melletti tanulást igénylő feladatok megoldásához, a területspecifikus LVM-nek sokkal kevesebb felcímkézett adatra van szüksége általános LVM-hez hasonló teljesítmény eléréséhez. Tehát velük érdemes próbálkozni az internetes képektől nagyon különböző vizuális adatok feldolgozásakor.
Az LVM-ek persze még gyerekcipőben járnak, területspecifikus változataik többféleképpen gyakoroltathatók, szöveggel kombinálva pedig területspecifikus nagy multimodális modellek dolgozhatók ki.