
A DeepSeek startup a techvilágot felforgató R1 modellje változásokat vetít előre. A kód és a súlyok ingyenes licenc alatt állnak, kereskedelmi és magáncélra egyaránt használhatók, például az R1 outputjaira épülő új modellek gyakoroltatására is. A modell explicit promptolás nélkül, az OpenAI munkái hatására tavaly markáns trenddé vált gondolatlánccal (Chain-of-Thought, CoT) működik.
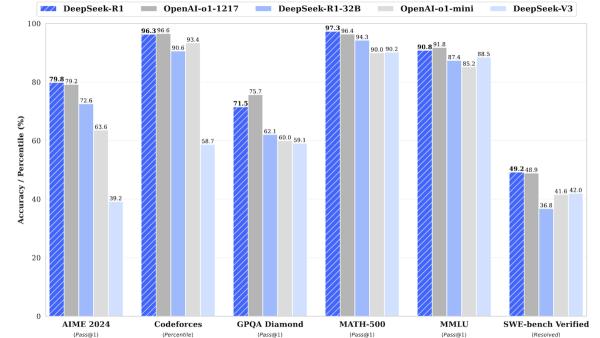
Az R1 a DeepSeek-V3-Base változata. Négy lépésben finomhangolták, hogy tudjon gondolatlánccal működni. Szakértői transzformer 671 milliárd paraméterrel, amelyek közül 37 milliárd bármikor aktív. 128 ezer input tokent dolgoz fel, a DeepSeek API-ján (alkalmazásprogramozói felületén) érhető el.
Az alapmodellt változatos technikákkal generált, többezer hosszú CoT-példán gyakoroltatták.
Csoportos relatív irányelv-optimalizálással, egy megerősítéses tanulás algoritmussal javítottak kihívással járó problémákra vonatkozó megoldó-készségét, majd további finomhangolással, az R1 fejlődő verzióival kb. 600 ezer választ generáltattak érvelési felszólításokra. Újabb 200 ezer nem-érvelő példával keverték össze. Ezeket a Deep-Seek-V3-Base alapján vagy gyakorló-adatkészletből generálták.
A következő, utolsó finomhangolásnál ismét megerősítéses tanulást használtak. Ezzel a lépéssel az érvelési problémák pontosságának növelésére ösztönözték a modellt, miközben javította segítőkészségét és amennyire tudták, a kártékony reakciós készséget is kigyomlálták belőle (magyarán szinte senkit sem gyaláz).
A kutatók hét kapcsolódó modellt adtak ki. A DeepSeek-R1-Zero hasonlít az R-1-hez, finomhangolása viszont teljes egészében megerősítéses tanulással történt. A Zero puszta ösztönzésre képes problémamegoldó stratégiákat kidolgozni – emelték ki a fejlesztők. De még valószínűbb volt, hogy összekever nyelveket, és olvashatatlan outputokkal áll elő.
Hat kisebb, másfél, hét, nyolc, tizennégy, harminckét és hetvenmilliárd paraméteres modellt is kiadtak. Négy a Qwen, kettő a Llama változatain alapul.




