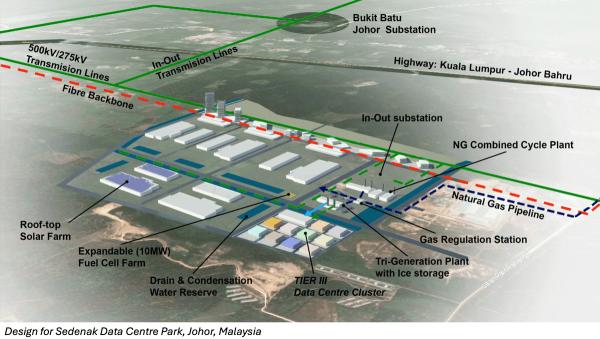
Az adatállomány növekedése miatt vállalatok kénytelenek adattárolásukat, alkalmazásaikat és szolgáltatásaikat decentralizálni, hogy a lehető legközelebb legyenek a végfelhasználókhoz. Például a hálózatok peremén, kihasználva az ottani „okos” tárgyak, mobiltelefonok, routerek, integrált hozzáférésű eszközök vagy éppen közeli mikro-adatközpontok stb. lehetőségeit.
Az elosztott számításokhoz tartozó peremszámítások (edge computing) lényege, hogy nem hagyományos adatközpontokon és nem is a felhőn alapulnak, hanem a számításokat és az adattárolást az adatforrás közelébe víve, minimálisra csökkentik a távolság miatti potenciális problémákat, például az akadozó sávszélességet. Olcsón és gyorsan működnek egy alapvetően egyszerű infrastruktúrában, és ha valami elromlik, a hibát is hamar megoldják.

Az amerikai techóriásokkal rivalizáló francia Mistral AI két 8 milliárd vagy kevesebb paraméteres nyelvmodellt mutatott be, amelyek elég kicsik ahhoz, hogy peremszámítás-eszközökön is fussanak. A Ministral 3B és a Ministral 8B több területen jobb teljesítményt nyújt, mint a Google és a Meta hasonló méretű modelljei: ismeret visszakeresés, józanész-alapú következtetés, többnyelvű szövegértés.
Az első modellt, a Mistral 7B-t tavaly mutatták be a nyíltforrású Apache licenc alatt. Azóta több méretben kísérleteznek modellekkel, alternatív architektúrákkal. Zárt modelleket szintén fejlesztenek, az eddigiek speciális feladatokra (kódgenerálás, képfeldolgozás stb.) használhatók.
A Mistral alkalmazásprogramozói felületén (API) hozzáférhető Ministral 8B nem kereskedelmi célra ingyen letölthető, a kereskedelmi használat üzleti licencszerződés tárgya. A 3B millió input és output tokenenként 0,04, a 8B 0,10 dollárba kerül.
A Ministral-család 131073 input tokent képes feldolgozni. A modellek úgy készültek, hogy természetes módon folytassanak interakciókat például valósidejű időjárási adatokat lekérő vagy intelligensotthon-eszközöket vezérlő külső API-kkal.
A 3B-t kisebb eszközökre, például okostelefonokra, a 8B-t nagyobbakra, például laptopokra találták ki. A teszteken kódolásban, matematikában, francia, német és spanyol nyelvű feladatokban is jól teljesítettek.