Az utóbbi másfél évben a generatív mesterséges intelligencia vált a legfontosabb infokom technológiává. A felhasználók száma napról napra nő, köztük egyre több gyártócég is alkalmazza, vezetőik optimisták. Az MIT (Massachusetts Institute of Technology) friss felméréséből kiderült, hogy az MI-fejlesztésekkel kapcsolatos ambíciók erősebbek a gyártószektorban, mint a többi ágazatok zömében.
A teljesen automatizált intelligens gyár integráns részét látják benne, növeli a termék- és folyamat-innovációt, csökkenti a gyártási ciklus időtartamát és a széndioxid-kibocsátást, hatékonyabbá tesz eszközöket és folyamatokat, eredményesebb lesz tőle a karbantartás és a biztonság – állítja sok gyártó.
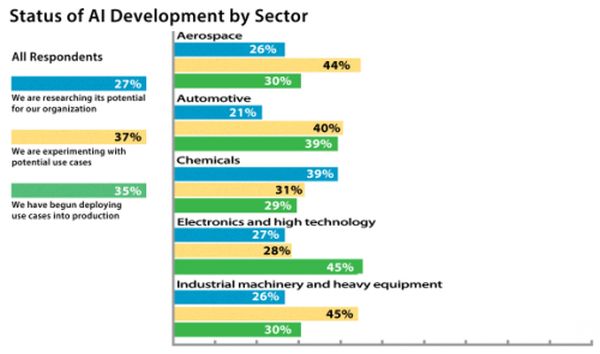
A felmérés készítői azt vizsgálták, hogy gyártók hogyan profitálnak MI esettanulmányokból. A szektor mesterséges intelligenciával valamilyen szinten dolgozó háromszáz képviselője vett részt benne.
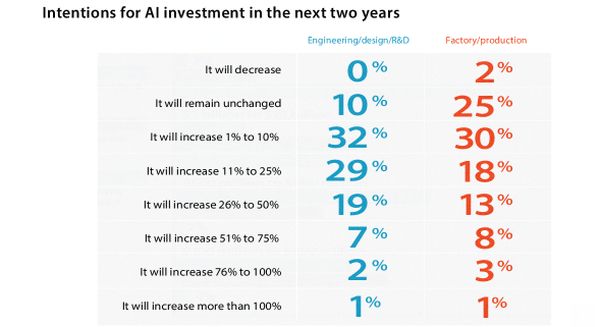
64 százalékuk kutatásokat vagy kísérleteket végez vele, 35 százalék már a gyártásban hasznosítja. Sokan kijelentették, hogy a következő két évben szignifikáns mértékben növelni igyekeznek MI-kiadásaikat. Akik még nem alkalmazzák a gyártásban, fokozatosan vezetik be.
Az MI méretezésének (skálázásának) a tehetség, a készségek és az adatok hiánya a legfőbb hátráltatói. Minél közelebb kerül a cég a gyártáshoz, annál markánsabbak ezek a problémák. A nem megfelelő adatminőség és szervezés szintén megnehezíti sikeres felhasználási esetek kidolgozását.
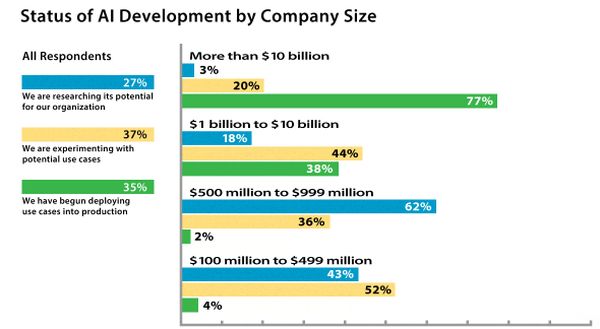
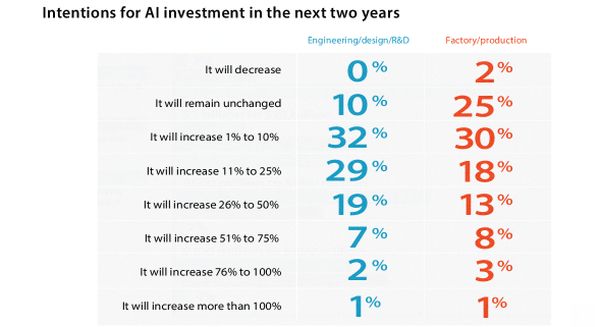
A legnagyobb cégek költik a legtöbbet, és az ő elvárásaik is a legmagasabbak. A mérnöki és tervezői területen a vezetők 58, gyári folyamatoknál 43 százaléka szerint a következő két évben cégük több mint 10 százalékkal növeli MI-költéseit.
Az MI miatti óhajtott nyereségek gyártási funkciókként változnak. A terméktervezés, a beszélgető MI és a tartalomkészítés a leggyakoribb felhasználási esetek, de a tudásmenedzsment és a minőség-ellenőrzés szintén fontosak.
Ha nincsenek megfelelő adatalapok, akadozhat a méretezés. A nem adekvát adatminőséget a megkérdezettek 57, a gyenge adatintegrációt 56, a rossz irányítást 47 százaléka említette, és csak minden ötödik megkérdezett rendelkezik meglévő MI-modellekben való használatra kész gyártóeszközökkel. Minél nagyobb a gyártó, annál problémásabbak a nem megfelelő adatok.
A méretezéshez a töredezettséget is kezelni kell. A gyártók többsége szerint az adatarchitektúra, az infrastruktúra és a folyamatok modernizálása nélkül nem megy az MI-alkalmazás. Az adatrendszerek mérnökök, tervezők és a gyár közötti interoperabilitásának javítása szintén kulcsfontosságú.