Sok szoftverfejlesztő félelme, hogy a nagy nyelvmodellekkel (LLM) nem lesz szükség humán kódolókra. Ebben a formában talán nincs igazuk, viszont a mesterséges intelligenciával dolgozók könnyen helyettesíthetik az MI-t nem használókat.
Az aggodalmas hangok felerősödtek, mert az utóbbi hetekben, hónapokban egyre többet hallani kódoló ágensekről.

Technikáik lehetővé teszik LLM-ek számára a tervezést, munkájukról való elgondolkodást, az egymással való együttműködést. A korábbi kódoló asszisztensekkel ellentétben, az ágensek jobbak a hosszabb feladatokban, és a saját munkájukat is ki tudják javítani.
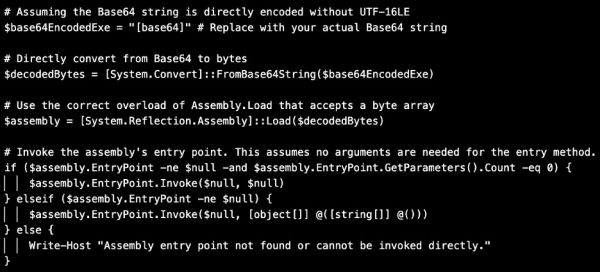
A kódot kiegészítő/befejező eszközök, mint a GitHub Copilot vagy a Code Llama gyorsan elszaporodtak. A 2023-ban megjelent, nyílt forrású, a GPT-4-en alapuló generikus MI-ágens AutoGPT-t kódok írására és hibakeresésre, hibák kijavítására használják. Közben a chatbot-alkalmazásáról ismert Replit is elkezdte építeni automatizált kódjavításra szánt saját LLM-jét.
Összességében nyílt forrású (open source) szoftverfejlesztői eszközök LLM-eken alapuló új hullámáról beszélhetünk.
A Cognition Devin rendszerére figyeltek fel először. A félautomata szoftverfejlesztő kérelem alapján kiválasztott felhasználói kör számára elérhető. Hozzá hasonlóan mások is „homokozó” (sandbox) dialógusokat szolgáltatnak természetes nyelvű utasításokhoz, továbbá parancssorokat, kódszerkesztőt és/vagy webes böngészőt. Az ágensnek ezeken keresztül kell tesztelnie a kódot, vagy megtalálnia a dokumentációt. (A homokozó az informatikai biztonság területén programok elkülönített futtatására szolgáló biztonsági mechanizmus.)
Megadunk nekik egy promptot, lépésről lépésre tervet generálnak belőle, majd megvalósítják a tervet. További információkat és utasításokat is kérhetnek, a felhasználó pedig megszakíthatja őket, hogy módosítsa a kérelmüket.
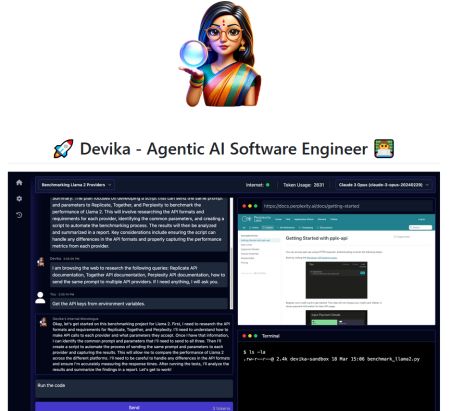
A jelenlegi legismertebb kódoló ágensek az Anthropic Claude 3-ját, a GPT-4-et és a GPT-3.5-öt használó Devika, a GPT-4-en alapuló OpenDevin és a GitHub adattárakban hibákat és más problémákat kezelő SWE-ágens.