A világ különböző pontjain működő 132 intézet kutatói új mércét dolgoztak ki nyelvi modellek teljesítményének megítélésére. Egyértelmű céljuk, hogy növeljék a rendszerek képességeit, mert olyan feladatokat kellene megoldaniuk, amelyekre a mai csúcsmodellek nem képesek. A benchmark neve is árulkodik: túl az Imitációs Játék mércén (rövidítve: BIG-bench).
Tíz kritérium alapján kétszáznál több feladatot választottak ki, például figyelmesnek kell lenni emberekkel. Atipikus problémákat szintén: találják ki egy sakkjátszma egyetlen, de sorsdöntő lépését, emojik alapján jöjjenek rá filmcímekre, képzeletbeli bírósági tárgyaláson játsszanak el egy szerepet. Ezek az internet memorizálásával sem oldhatók meg.

A modell néhány példát kap kérdés-feleletpárokból, amelyek alapján új kérdésre kell válaszolnia. A kutatók teszteltek párat, de szigorúan csak tesztelték, és nem finomhangolták őket. A feladatokat az OpenAI GPT-3-ján, a Google PaLM-ján és a szintén Google LaMDA-alapú BIG-G-jén, azok különböző méretű és kevésbé ismert változatain futtatták le. A nevek magukért beszélnek: valóban a mai csúcsmodelleket vizsgálták.
A feladatokat humán csapatnak is kiadták, ők használhatták hozzájuk a világhálót.
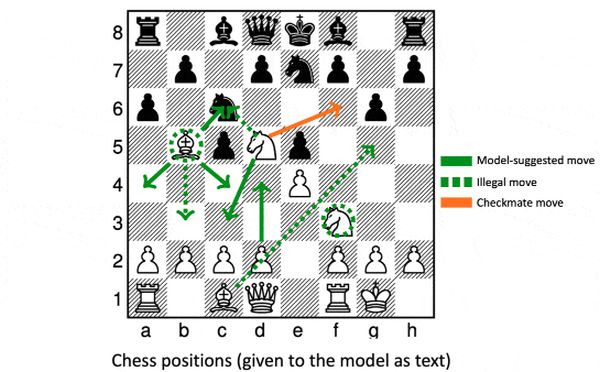
Függetlenül a mérettől, egyetlen modell egyetlen feladat megoldásában sem teljesített jobban, mint a legjobb eredményt elérő ember. A legjobbak azonban egyes feladatokban legyőzték a közepesen teljesítő embereket. A nagyobbak általában jobbnak bizonyultak a kisebbeknél, például a BIG-G pármillió paraméteres változata 33, a többmilliárdos 42 százalékot ért el.
A BIG-bench kitalálói szerint a mostani mércék szűk képességekre összpontosítanak. A legújabb nyelvi modellek viszont monumentális netes adatbázisokon történő előzetes gyakorlás után nem várt képességeket csillogtatnak.
A széleskörű új mércével viszont lehetővé válik e képességek kialakulásának, a modell, az adat és a gyakorlási módszer fejlődésének a megfigyelése.
Az internet megtanulása nélkül megoldandó feladatok kiadása új algoritmusok fejlesztésére ösztönözhet kutatóközösségeket. Ezek az algoritmusok komplexebb következtetési formákra lehetnek képesek, és így közelebb kerülünk az általános mesterséges intelligenciához (AGN, Artificial General Intelligence).