A Google által néhány éve felvásárolt londoni DeepMind legendás mesterséges intelligenciája, AlphaGo Zero góban, sakkban és sógiban egyaránt emberfelettit teljesít. Más területeken, például klasszikus Atari-játékokban az R2D2 nevű MI nyújt hasonlót.
DeepMind-kutatók eldöntötték, hogy mély megerősítéses tanulással mindkét területen – táblás és videojátékokban – egyaránt eredményes, a két játéktípusban mindenkit verő MI-t fejlesztenek. A MuZero nevű új modellre AlphaGo Zero technikáit alkalmazták. Csakhogy míg AlphaGo Zeronak szüksége van a játékszabályok ismeretére, MuZeronak nincs.

Táblás játékoknál (sakk, go stb.) ketten játszanak, és csak egyetlen kimenet létezik: vagy nyerünk, vagy veszítünk. Videojátékokban egy játékos is lehet, aki aztán azonnali jutalomban részesül. MuZero egy világmodell megtanulásával, valamint az AlphaGo Zero-féle keresés elsajátításával megfelel az összes különböző feltételnek.
A játék minden egyes pontján egy adott lépés kimeneteit, és a lépés hatására a győzelem esélyeit mérlegeli. A lehetséges következményeket több komponens segítségével elemzi.
Az állapot-megjelenítő almodell a játék aktuális állásáról kivonatol információkat, amelyekkel egyszerűsített leírást készít erről az állapotról.
A leírás alapján az érték és irányelv almodell előrejelzi a várható jutalomhoz szükséges optimális lépést.
A dinamika és jutalom almodell a játék következő állapotát prognosztizálja, és megmondja, mi az azonnali jutalom egy-egy különleges cselekedet esetén.
Az érték és irányelv almodell minden egyes időlépésnél több lépéssel előretekintve keresi a potenciális kimeneteket, míg a dinamika és jutalom almodell sok jövőbeli mintát készít hozzájuk. Mindezek után és mindezeket figyelembe véve, MuZero megteszi a létező legjobb lépést, és elnyeri méltó jutalmát.
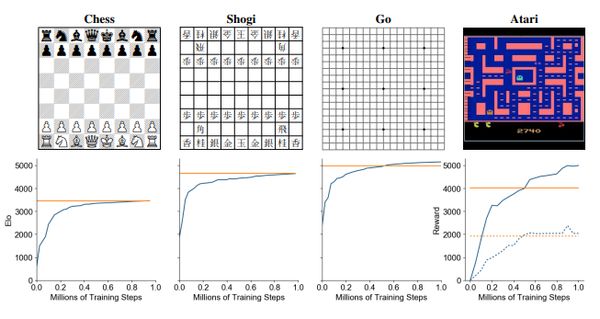
Az eredmények nem maradtak el, MuZero sakkban, sógiban és góban kevesebb számítással érte el AlphaGo szintjét. Atari-játékokban pedig kevesebb gyakorlással döntötte meg a korábbi világcsúcsokat.
Bebizonyosodott, hogy a szintézis működik. Korábbi modellek vagy pontos tervezéssel (táblás játékok), vagy bonyolult dinamikák elsajátításával (videojátékok) értek el szép eredményeket. MuZero viszont egyértelművé tette, hogy egyetlen modell képes mindkettőre.