
Fényképet kvázi festménnyé varázsoló, de képek ecsetvonásokkal történő reprodukálására is képes ideghálót fejlesztettek a kínai Baidu, a Nanjing és a Rutgers egyetemek kutatói. Egy új módszerrel rendszerük gyakorlóadat nélkül elsajátítja ezeket a képességeket.
A Paint Transformer ugyanis a képeket az általa tanulóadatok nélküli gyakorlás közben generált festmények reprodukálásával alakítja át festményekké.

Egy húsvér festő általában a háttérrel kezdi a képet, amelyet előtérrel, részletekkel egészít ki. A modell háttér-, majd előtér-ecsetvonások generálásával utánozza ezeket a folyamatokat, és megtanulja a reprodukálásukat.
Az eredmény további részekre bontásával finomabb részleteket is bele tud vinni a képbe. A véletlenszerűen generált ecsetvonások megtanulása remek tréning nem véletlenszerű anyagok, például fényképek újraalkotásához.

Egyszerre nyolc ecsetvonással fest. Gyakorlás közben random generál „nyolc-vonásos” hátteret, majd előteret, aztán elsajátítja a kettő közti különbségek minimalizálási módját. Ezt a háttér további nyolc ecsetvonással történő átalakításával éri el.
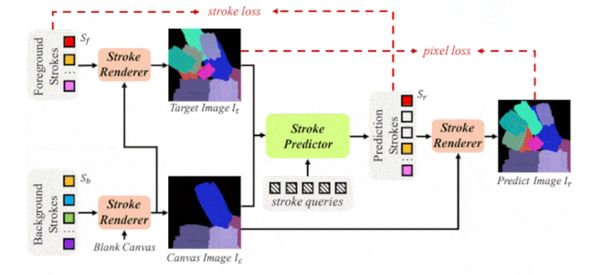
Gyakorláskor különféle konvolúciós ideghálók generáltak háttér-megjelenítéseket, valamint hátteres-előteres festményeket. Egy átalakító háló elfogadta ezeket, a különbségek nyolc ecsetvonásos minimalizálásához kiszámolta a pozíciókat, a formákat és a színeket. Ezeket a paramétereket elküldte a vonásokat renderelő lineáris modellnek, amely az elvárásoknak megfelelően alakított át képet, hátteret.
A rendszer a random generált háttér-előtér kombináció és az output pixelei, valamint a véletlenszerűen generált ecsetvonás-paraméterek és az átalakító háló által kiszámoltakat kombinálta össze. A fénykép és a vászon közti különbséget megint nyolc ecsetvonással minimalizálta, utána mindkét képet négyzetekre osztotta, majd megint jöttek az elmaradhatatlan ecsetvonások. A négyzeteket további négy alkalommal újabb négyzetekre osztotta, amelyekbe megint festett. A részeket végül egyetlen kész festménnyé integrálta.
Kevesebb és szélesebb ecsetvonásokkal dolgozik, mint egy ismert optimalizáló módszer, míg egy megerősítéses tanulás megközelítéssel az inputhoz nagyon hasonló output jött létre. Utóbbinál sokkal gyorsabban tanult (3,79 kontra 40 óra), következtetéseit mindkettőnél hamarabb hozta meg. Eközben úgy tanult meg festeni, hogy egyetlen létező festményt nem látott, tehát nem kellett többmillió fotó és festmény egyeztetésével bíbelődnie.
A megközelítés a fénykép-szerkesztésben és a 3D modellezésben egyaránt könnyen elterjedhet.




