
A gépi tanuláshoz és a gyakorláshoz használt adatsorok energiafogyasztása egyre több problémát vet fel.
Egy, a mélytanulás széndioxid-lábnyomáról szóló 2019-es tanulmány szerzői kimutatták, hogy egyetlen nagy nyelvi modell begyakoroltatásának károsanyag-kibocsátása annyi, mint egy átlagautóé öt év alatt. A negatív folyamatot megállítandó, tavaly az ML Commons gépitanulás-konzorcium nemzetközi energia-hatékonysági tesztet vezetett be. Szintén tavaly tanulmány jelent meg a nagy transzformer modellek energiahasználatáról, és kiderült: következtetésnél magasabb, mint a tréningek során.
A károsgáz-kibocsátás klímakatasztrófa-hatásai közismertek. 2020-ban az adatközpontok feleltek a globális energiahasználat egy százalékáért – azt viszont nem tudni, hogy ebből mennyi a mesterséges intelligenciáé.
Gépitanulás-szakértőknek mindenesetre lehetőségükben áll gondosan megválasztani, hogy mikor és hol gyakoroltassák modelljüket – állítja egy nemzetközi kutatócsoport.
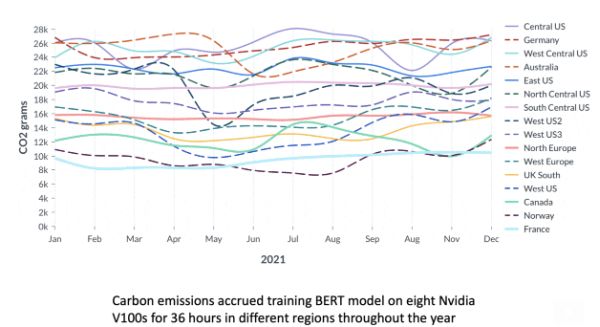
Az Allen Institute for AI, a Hugging Face, a Microsoft, a Washington Egyetem, a CMU (Carnegie Mellon University) és a Jeruzsálemi Héber Egyetem szakemberei ugyanis felhőszerverek gépitanulás-modellek gyakoroltatása közbeni energiakibocsátását mérő módszert dolgoztak ki.
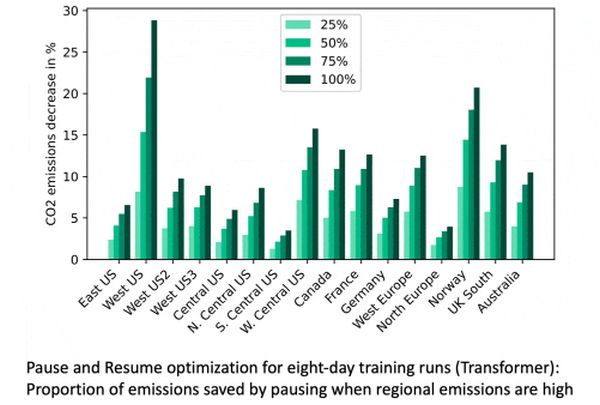
Kiderült, hogy a modell mérete mellett a szerver helyszíne és a tréning időpontja, a napszak a legfontosabb változók.
Sokat spórolhatunk, ha alacsony kibocsátású régióban, például Norvégiában vagy a francia Alpokban gyakoroltatunk egy modellt. Például az USA középső részével vagy Németországgal összehasonlítva, akár hetven százalékot is megtakaríthatunk, azaz ha az utóbbi helyekről mondjuk a norvég fjordok közelébe költöztetjük az MI-t (más kérdés, hogy ez mennyire praktikus, vagy sem).
A napszakbeli különbségek kevésbé drasztikusak, de jelentősek – például nyolc százalékot takaríthatunk meg, ha éjfélkor, és nem reggel hatkor kezdünk.
Persze minél nagyobb a modell, annál markánsabbak ezek a különbségek.




