
A közvélemény egyelőre a mesterséges intelligencia által generált szövegekre, képekre figyel, pedig a zenében is történt előrelépés. A Google és a párizsi Sorbonne Egyetem kutatói ugyanis bemutatták a szöveges leírásokból muzsikát létrehozó MusicLM rendszert.
Természetes nyelvű leírások és zenefelvétel párjaik egyelőre ritkák, ezért joggal merül fel a kérdés: hogyan gyakoroltathatók szöveget zenévé alakító programok?
Eddig a modelleket a kapcsolódó szöveg és zene ugyanahhoz a beágyazáshoz való társítására tanították. Így vált lehetővé a nagy mennyiségű felvétel alapján történő zenegenerálás, pontosabban újjáalkotás. Utána a modell levonta a következtetést, és szöveges utasítást (prompt) készített a zenékhez.
A MusicLM 24 kHz felbontású, harminc másodperces audióklipek újjáalkotását tanulta meg. 280 ezer órányi felvételből álló, nem nyilvános korpuszt használt hozzá.
A kihívás nagyságát érzékelteti, hogy a hangot három különböző aspektusból kellett modelleznie, ami persze árnyalta is a munkáját. A szavak és a zene közti kapcsolat az első. Nagyszabású kompozíció, például egy nyitány a második, amelyben hozzáadott dallamok ismétlődnek. Kisléptékű részletek, például egy dobhang megjelenése és elhalása a harmadik.
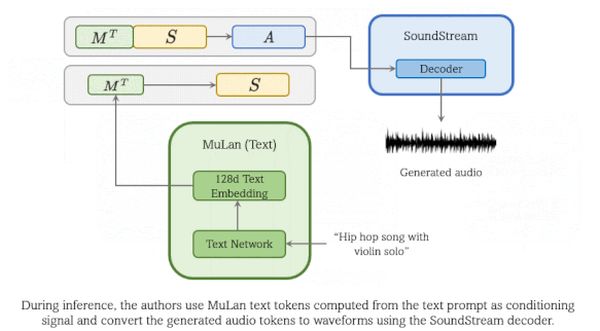
A kutatók mindhárom aspektust különféle tokenekkel reprezentálták, amelyeket előzetesen betanított, különböző rendszerek generáltak.
Ugyanabból az audióklipből az egyik (MuLan transzformer) hang-szöveg, a másik (w2v-BERT) szemantikus, a harmadik (SoundStream önkódoló) akusztikus tokeneket dolgozott ki. A hang-szövegesekből transzformerek szemantikusokat, a szemantikusokból és a hang-szövegesekből egy másik transzformer csoport akusztikusokat hozott létre. SoundStream dekódolója a második csoport tokenjeiből generált zenei klipet.
A fejlesztők egy szöveg-zene adatsor ezer leírását MusicLM-be és két másik hasonló modellbe, Riffusionbe és Mubertbe táplálták. A hallgatóknak el kellett dönteniük, melyik passzol leginkább az adott szöveghez. Az adatsor hivatásos zenészekkel felvett eredeti anyagait is választhatták.
Mubert 9,3, Riffusion 15,2, MusicLM 30 százalékot ért el. Legjobban, 45,4 százalékot a humán muzsikusok teljesítettek. A hallgatóság nem a zene minősége, hanem kizárólag a szöveghez való kapcsolódás alapján döntött.




