 A DALL-E 2 és a ChatGPT kevesebb mint egy éve indult világhódító útjára. A közben eltelt időszakban a generatív MI töretlen fejlődését láthattuk, és a fejlődés tempója egyelőre nem lassul.
A Google, a Meta és a Microsoft mellett most már az Amazon is bekapcsolódott a szöveg- és képgeneráló…
A DALL-E 2 és a ChatGPT kevesebb mint egy éve indult világhódító útjára. A közben eltelt időszakban a generatív MI töretlen fejlődését láthattuk, és a fejlődés tempója egyelőre nem lassul.
A Google, a Meta és a Microsoft mellett most már az Amazon is bekapcsolódott a szöveg- és képgeneráló…
Az Neumann Társaság blogja a legfejlettebb infokom technológiákról
Jelenből a Jövőbe
Kevés a számítási kapacitás?
 Nagy a kereslet a mesterségesintelligencia-piacot gépi úron generált szövegekkel és képekkel kiszolgáló startupok termékei iránt, csakhogy még a legígéretesebbek sem működnek a fejlesztéshez, teszteléshez és a modell működtetéséhez nélkülözhetetlen szerverek nélkül. Remek termékek fejlesztése…
Nagy a kereslet a mesterségesintelligencia-piacot gépi úron generált szövegekkel és képekkel kiszolgáló startupok termékei iránt, csakhogy még a legígéretesebbek sem működnek a fejlesztéshez, teszteléshez és a modell működtetéséhez nélkülözhetetlen szerverek nélkül. Remek termékek fejlesztése…
Hogyan veszítették el az MI nagyágyúk a chatbot-háborút, legalábbis az első csatáját?
 Miközben a mesterséges intelligenciával leginkább foglalkozó nagyágyúk rengeteg pénzt és időt fektettek a piacot megcélzó, kereskedelmi beszédtechnológiákba, beszélgető appokba, addig a Microsoft egy hatalmas ugrással, az OpenAI nagy nyelvmodelljeivel (large language models, LLM), azokat…
Miközben a mesterséges intelligenciával leginkább foglalkozó nagyágyúk rengeteg pénzt és időt fektettek a piacot megcélzó, kereskedelmi beszédtechnológiákba, beszélgető appokba, addig a Microsoft egy hatalmas ugrással, az OpenAI nagy nyelvmodelljeivel (large language models, LLM), azokat…
A Microsoft megszünteti etikai csoportját
 A felelős mesterséges intelligencia kérdése ugyanolyan fontos, mint bármikor volt. A generatív MI-t körbelengő mostani aranyláz azonban a legújabb fejlesztésekkel megvalósítható még nagyobb profitra, és nem az esetleges morális problémák megoldására ösztönzi a vállalatokat. Felgyorsítják a modellek…
A felelős mesterséges intelligencia kérdése ugyanolyan fontos, mint bármikor volt. A generatív MI-t körbelengő mostani aranyláz azonban a legújabb fejlesztésekkel megvalósítható még nagyobb profitra, és nem az esetleges morális problémák megoldására ösztönzi a vállalatokat. Felgyorsítják a modellek…
Messze még az általános mesterséges intelligencia, de már közelebb vagyunk hozzá, mint egy éve ilyenkor
 Az IBM Watson nevű mesterséges intelligenciája – a névválasztás a nagyvállalat első elnöke Thomas J. Watson előtti tisztelgés volt – 2011-ben a Jeopardy! televíziós vetélkedőn legyőzött két húsvér bajnokot. 2015-ben a ma már a Google-hoz tartozó DeepMind bemutatta a go világranglista negyedik…
Az IBM Watson nevű mesterséges intelligenciája – a névválasztás a nagyvállalat első elnöke Thomas J. Watson előtti tisztelgés volt – 2011-ben a Jeopardy! televíziós vetélkedőn legyőzött két húsvér bajnokot. 2015-ben a ma már a Google-hoz tartozó DeepMind bemutatta a go világranglista negyedik…
A digitális kor legsikeresebb üzleti modelljei
 A 21. században a digitális befektetők, a hagyományos üzleti modelleket felforgatva, a bevételszerzés és a fogyasztók kiszolgálásának új módjait keresik. Tevékenységüket a desktop számítógéptől a felhőszámításig, a mesterséges intelligenciáig, az infokom technológiák több diszruptív hulláma tette és…
A 21. században a digitális befektetők, a hagyományos üzleti modelleket felforgatva, a bevételszerzés és a fogyasztók kiszolgálásának új módjait keresik. Tevékenységüket a desktop számítógéptől a felhőszámításig, a mesterséges intelligenciáig, az infokom technológiák több diszruptív hulláma tette és…
Keresőmotorok háborúja
 A jövő internetes keresését mostani és majdani technológiák egyformán alakítják. E technológiák egyike, a nagy nyelvmodellek (LLM) gyakori problémája a ténybeli pontatlanság, a szöveggenerálás dokumentum-visszakereséssel való párosításában viszont komoly a fejlődési potenciál, megoldást jelenthet a…
A jövő internetes keresését mostani és majdani technológiák egyformán alakítják. E technológiák egyike, a nagy nyelvmodellek (LLM) gyakori problémája a ténybeli pontatlanság, a szöveggenerálás dokumentum-visszakereséssel való párosításában viszont komoly a fejlődési potenciál, megoldást jelenthet a…
A Microsoft vezérigazgatója szerint nem szabadul el a mesterséges intelligencia
 A Google teljesen uralja a keresőmotor-piacot, a területen lényegében egyeduralkodó. Az állóvizet borzolhatja, hogy a Microsoft mesterséges intelligenciát integrált a megújított Bing keresőbe, ráadásul nem is akármilyen MI működteti, hanem az OpenAI híres ChatGPT-jének az egyik változata.
A…
A Google teljesen uralja a keresőmotor-piacot, a területen lényegében egyeduralkodó. Az állóvizet borzolhatja, hogy a Microsoft mesterséges intelligenciát integrált a megújított Bing keresőbe, ráadásul nem is akármilyen MI működteti, hanem az OpenAI híres ChatGPT-jének az egyik változata.
A…
Szövegből zenét hoz létre a mesterséges intelligencia
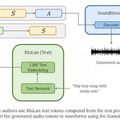 A közvélemény egyelőre a mesterséges intelligencia által generált szövegekre, képekre figyel, pedig a zenében is történt előrelépés. A Google és a párizsi Sorbonne Egyetem kutatói ugyanis bemutatták a szöveges leírásokból muzsikát létrehozó MusicLM rendszert.
Természetes nyelvű leírások és…
A közvélemény egyelőre a mesterséges intelligencia által generált szövegekre, képekre figyel, pedig a zenében is történt előrelépés. A Google és a párizsi Sorbonne Egyetem kutatói ugyanis bemutatták a szöveges leírásokból muzsikát létrehozó MusicLM rendszert.
Természetes nyelvű leírások és…
A Google hivatalosan bejelentette Bardot, a ChatGPT vetélytársát
 Sundar Pichai, a Google vezérigazgatója február hatodikai blogposztban jelentette be a cég lekérdezéseket megválaszoló, csevegésben részt vevő kísérleti beszélgető mesterségesintelligencia-szolgáltatását. A Bard nevű szoftvert most „megbízható tesztelők” csoportja használja, pár héten belül…
Sundar Pichai, a Google vezérigazgatója február hatodikai blogposztban jelentette be a cég lekérdezéseket megválaszoló, csevegésben részt vevő kísérleti beszélgető mesterségesintelligencia-szolgáltatását. A Bard nevű szoftvert most „megbízható tesztelők” csoportja használja, pár héten belül…