
A big data korában eljuthatunk odáig, hogy a kínálat szintjén nem lesz annyi adat, mint amekkora a kereslet. A paradoxon oka egyszerű és logikus: egyre nehezebb kielégíteni az egyre „nagyobb étkű” gépitanulás-modellek szükségletét.
Az Epoch AI kutatói szerint a szöveges adatokkal már idén bajok lehetnek, még ebben az évben jelentkezhet a hiány. A vizuális adatokkal minimum egy évtizeden belül várható hasonló helyzet.
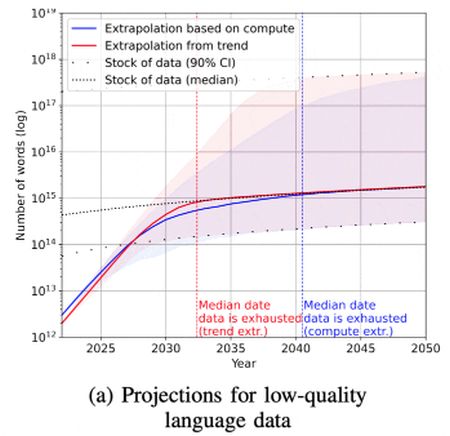
A kutatók a jövőbeli szükségleteket, a hozzáférést, a címkézetlen nyelvi és képi adatokat hasonlították össze. A nyelvi adatok kiértékelésénél a Wikipediára, az Arxivra (elektronikus elő- és utónyomatok nyílt hozzáférésű tárháza), digitális könyvekből álló könyvtárakra összpontosítottak. Mivel ezeket az anyagokat szerkesztői és minőségkontrollnak is alávetik, különleges értéket jelentenek nagy nyelvmodellek gyakoroltatásánál.
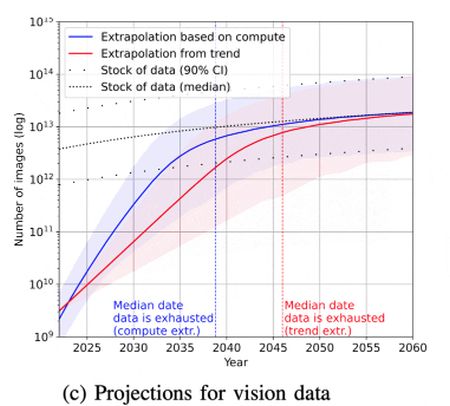
Vizuális adatokként YouTube, Instagram, Snapchat, WhatsApp és Facebook álló- és mozgóképeket használtak.
Arra a következtetésre jutottak, hogy a nagy modellek trenírozásához szükséges adatsorok mérete sokkal gyorsabban fog növekedni, mint az adatellátás.
A csúcsminőségű nyelvi adatok mennyisége évi négy-öt százalékkal növekszik. A szöveges adatsoroknak viszont minden tizenegy-huszonegy havonta meg kell duplázódniuk, azaz az egyensúly nehezen tartható fenn, és a hiány 2023 és 2027 közöttre prognosztizálható. Az adatminőség csökkentésével néhány év „menedék” várható, és így realisztikusabban a 2030 és 2040 közötti évtizedre várható a hiány.
A vizuális adatellátás évi nyolc százalékkal növekszik, míg az adatsorok képmennyisége két és fél-négyévente duplázódik. Tartva ezt a növekedési ütemet, valamikor 2030 és 2060 között lesz tapasztalható a hiány.
Az Epoch AI korábban már kiszámolta a gyakorló adatsorok méretbeli és történelmi növekedést. A legdinamikusabb növekedést a legnagyobb csúcsminőségű szöveges adatsorokon, a legalacsonyabbat a vizuális sorokon figyelték meg.
A jövőbeli számok, statisztikák viszont nemcsak természetüknél fogva, hanem más tényezők miatt is pontatlanok lehetnek – javulhat a modellek adathatékonysága, a szintetikus adatok jobb minőségűvé válhatnak, új adatforrások tűnhetnek fel.
Ha például tényleg elterjed at önvezető autó, hatalmas mennyiségű vizuális anyag generálódik.




