A Google által néhány éve felvásárolt londoni DeepMind három tanulmányt tett közzé a nagy nyelvi modellek lehetőségeiről. Két transzformer-modellel többféle nyelvi feladatot próbált különféle naprakész technikákkal megoldani. Ugyanakkor, ha ezen modellek folyamatosan javulnak, a velük járó kockázatok is nőnek – hangsúlyozza a DeepMind.
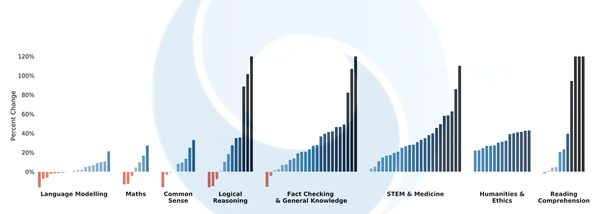
Az OpenAI GPT-2-jén alapuló Gopher 280 milliárd paraméterrel dolgozik, és a 10,5 terabájtos úgynevezett Massive Text korpuszon gyakorolt. A korpusz sajtóhírekből, könyvekből, Wikipédia-szócikekből és más weboldalakból áll. 152, köztük viszonyítási alapnak számító feladatokon tesztelték, és az elért nyolcvan százalékos eredmény mérföldkőnek számít.
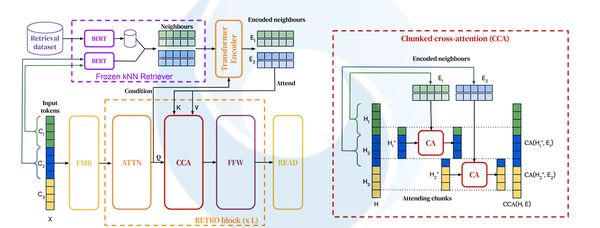
Egy másik modell, a RETRO (Retrieval Enhanced Transformer) közel hétmilliárd paraméteren ért el a Gopherhez hasonló teljesítményt. Kisebb mérete ellenére a Massive Text korpusz számos anyagát feldolgozta és integrálta egybe. (A modelleket megjelenítő ábrák ugyan bonyolultak, de nem blogunk rendeltetése, hogy az algoritmusokat teljes komplexitásukban megismertessük, inkább csak érzékeltetni szeretnénk, milyen léptékű feladatokról van szó.)
A harmadik tanulmány az ezek a nyelvi modellek által generált huszonegy közösségi és etikai kockázatot sorolja fel (taxonómiát kínál). Például nem szándékosan terjeszthetnek sztereotípiákat, sértő nyelvi kifejezéseket, hozzájárulhatnak a káros félretájékoztatáshoz, hamis információk terjedéséhez, érzékeny adatok kiszivárogtatásához, de még a túlzott és káros energiahasználathoz is.
Mindezt nem szándékosan teszik, a kockázat viszont attól még fennáll. Az anyag szerzői e kockázatok csökkentésére javasolnak stratégiákat – jobb adatsorok kidolgozását, átláthatóbb modellek építését.
A Gopher és a RETRO szembe megy az egyre nagyobb nyelvi modellekről szóló trendekkel. A RETRO lekérdező stratégiája viszont a legfrissebb kutatások eredményeit felhasználva, külső tudásbázisokkal, ismeretforrásokkal kapcsolja össze a nyelvi modelleket.
A Gopher paraméterei a Microsoft-Nvidia Megatronjával (530 milliárd) és a Kínai MI Akadémia Wu Dao 2.0-jával (1,75 trillió) összehasonlítva egyaránt szerények, míg a RETRO külső információgyűjtési lehetőségei a Facebook RAG és a Google REALM rendszeréhez hasonlóak. Az adatbázis frissíthető, és így a modell a következő betaníttatásnál újabb és akkurátusabb adatokkal dolgozhat.
A természetesnyelvi-modellek az utóbbi években komoly fejlődésen mentek keresztül, de még így is sok munkát kell elvégezni rajtuk, hogy minél szélesebb körben kerüljenek alkalmazásra. A DeepMind erre kínál úgy lehetőségeket, hogy egy modellnek ne kelljen mindent megtanulnia, viszont külső forrásokból is tudjon következtetni.