
A trillió paraméteres nyelvi modellek kialakulóban lévő új generációjának gyakoroltatásához jelentős mennyiségű számítás szükséges. Ez a mennyiség komoly növekedés a néhány évvel korábbihoz képest, és az energiahasználat szintén szignifikáns mértékben nő.
Megoldás lehet, ha a hálózatnak csak egy része aktív. Az elhasznált kapacitás drasztikusan csökken, rendkívüli eredmények viszont még így is elérhetők – vonták le a következtetést a Google kutatói.
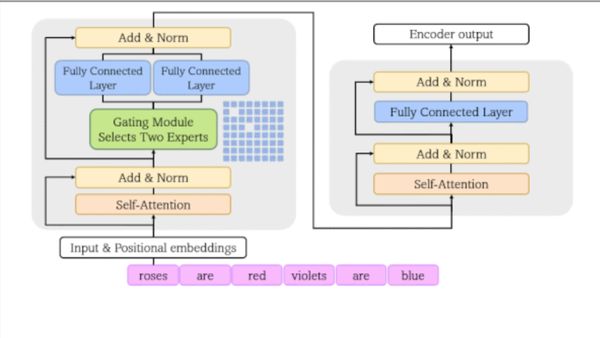
Generalizált – trillió paraméteres – modelleket (GLaM) fejlesztettek több nyelvi feladat megoldására. A vállalat korábbi Switch technológiájához hasonlóan ezek is szakértői rétegek keverékét (mixture-of-experts, MoE) használják, hogy az input függvényében megállapítsák, a hálózat melyik részeit kell aktiválni. A fejlesztést ismertető anyag alapján jobban látjuk, hogy az MoE hogyan spórolhat meg időt és elektromosságot praktikus nyelvi feladatok megoldása közben.
A mesterséges ideghálók paramétereinek számában a teljesítmény (minél nagyobb, annál jobb) és az energiaköltség (minél kevesebb, annál jobb) közötti kompromisszumnak kell érvényesülnie.
Az MoE architektúrák paramétereik különböző részhalmazait használják a különböző példákból történő tanuláshoz. Minden egyes MoE réteg tartalmaz egy úgynevezett vanília idegháló-csoportot, vagyis szakértőket, előttük egy kapumodul, amely az input alapján eldönti, hogy melyiket kell használni. Így válik lehetővé, hogy a különböző szakértők meghatározott példatípussal tudjanak foglalkozni. A hálózat kevesebb energiát fogyaszt, és többet tanul, mint amennyit az adott részhalmaz mérete alapján feltételeznénk.
A kutatók MoE rétegekkel felvértezett transzformer modellt gyakoroltattak. Szövegszekvenciában a következő szót vagy a szó egy részét kellett kitalálnia. 1,6 trillió szóból álló, webes, könyv, közösségimédia-beszélgetés, fórum és újságcikk alapján összeállított korpuszon trenírozták, majd 29 nyelvi feladat megoldására finomhangolták. Hét kategóriában, például kérdések megválaszolásában, logikus következtetésben kellett tevékenykednie.
Az 1,2 trillió paraméteres GLaM gyakoroltatásához 456 megawatt/óra energia elegendő volt, míg a 175 milliárd paraméteres GPT-3-hoz óránkénti 1,287 megawatt volt a fogyasztás, ráadásul a GLaM hat, illetve öt kategóriában jobban is teljesített.
Az alacsonyabb energiafogyasztás melletti nagyobb számítási teljesítménnyel, mérnököknek könnyebb lesz naprakész modelleket trenírozniuk. Közben kevesebb lesz a széndioxid-kibocsátás, csökken a mesterséges intelligencia negatív környezeti hatása.




