
A Stanford Egyetem kutatói bemutatták a rajintelligencia (swarm intelligence) technológián alapuló Osztatlan MI orvosi megoldást. Nyolc radiológus az MI-n keresztül folytatott interakciót egymással, és kiderült, hogy a tüdőgyulladás a mellkasról készült röntgenfelvételek alapján történő diagnosztizálásánál a mesterségesintelligencia-ember csapat jobb eredményt ér el, mint orvosok és gépitanulás-programok külön-külön.
MI-alapú prediktív technológiát korábban például a Kentucky Derby, Oscar-díjak, a 2016-os kosárlabda World Series győzteseinek előrejelzésére használtak. A Kentucky Derby első négy helyezettjét eltalálta, az Oscaroknál pontosabban jósolt, mint a kritikusok, s World Series esetében pedig helyesen a korábban 108 évig sikertelen Chicago Cubs-t tippelte befutónak.
A technológia most már az egészségügyi szektorban is debütált, és bebizonyosodott, hogy hatékonyabb, ha nem helyettesíti az orvosokat, hanem együtt dolgozik velük.
„Az emberi ismeretek, bölcsesség és tapasztalat kihagyása helyett arra kell összpontosítani, hogy az MI-t mindezek még magasabb szintre emelésére használjuk fel” – nyilatkozta az egyik legismertebb közösségi állatra, a méhekre utaló „kaptárelme” (hive mind) rendszert fejlesztő cég alapító-vezérigazgatója, Louis Rosenberg.
A technológia lényege az MI-algoritmusok és az emberi input összekombinálása. Pontosságáról annyit, hogy eltalálta a Super Bowl végeredményét, a TIME Magazin Év Emberét stb.
A tüdőgyulladással sincs könnyű dolga, mert a röntgensugaras diagnózis sok más betegségre hasonlít.
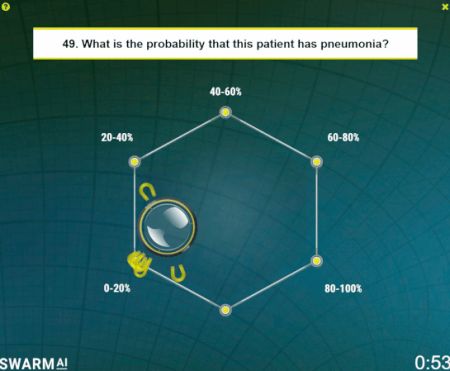
A nyolc radiológus nyílt forrású adatsor 50 mellkasi képét tanulmányozta. Mindegyiknek meg kellett mondania a tüdőgyulladás valószínűségét. Egyszerű „igen” vagy „nem” helyett, a méhek kollektív döntéshozásáról modellezett mesterséges intelligenciával együttműködve, árnyaltabb véleményt hoztak. Az összes röntgenképet valósidőben, szimultán nézték, súlyozták, minősítették. Kicsi ikont irányítottak, amellyel saját véleményükön alapuló konszenzust sugallhattak a többieknek. Közben az algoritmusok monitorozták a viselkedésüket, az ikon gyorsabb-lassabb stb. mozgatására alapozva következtetettek arra, hogy egy-egy orvos mennyire biztos az állításában.
Az ember-gép rendszer 33 százalékkal jobban teljesített a humán orvosoknál, a CheXNet gépitanulás-programot pedig 22 százalékkal múlta felül.




