A mesterséges intelligencia okostelefonos térhódítása már a ChatGPT színrelépése előtt megkezdődött, a generatív MI diadalútja viszont látványosan felgyorsította folyamatot. Már 2022 végén, 2023 elején egyértelmű volt, hogy a chatbotok és társaik okostelefonos integrációja visszafordíthatatlan. De miért is akarnánk visszafordítani?
Az idei androidos és iPhone-frissítéseket nem meglepő módon az MI fogja uralni. A legtöbb a Google-tól jön majd, viszont nem árt, ha odafigyelünk rájuk, mert nagyon megváltoztathatják készülékhasználatunkat.

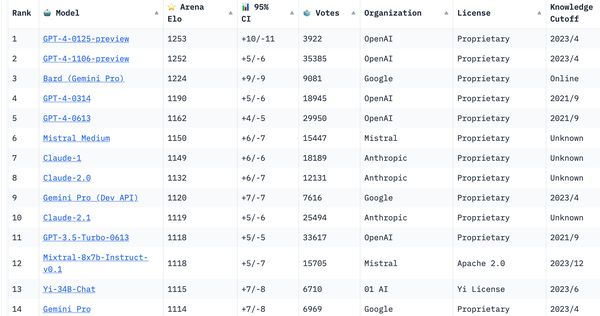
A cég nemrég nevezte át ChatGPT-szerű chatbotját, a Bardot, és az új brand mellé emlékeztetőt is fűzött. Az emlékeztetés inkább figyelmeztetés, hogy a mamutvállalat milyen adatokat gyűjt miközben a mesterségesintelligencia-alkalmazását használjuk.
Bard most már Geminiként fut, és a magánadatok, a privacy védelmében a Google kimondta, hogy az MI-vel folytatott interakció során a következőket gyűjti össze: infókat tartózkodási helyünkről, felhasználási adatokat, és mindenféle visszajelzést tőlünk.
Humán kiértékelők elolvashatják ezeket, megjegyzéseket fűzhetnek hozzájuk, feldolgozhatják beszélgetéseinket. A nagyvállalat az anonimitást megőrizve, igyekszik megvédeni a privacy-t, azaz a beszélgetéseket szétválasztja a Google-fiókoktól még mielőtt a kiértékelő személyek hozzájuk férnének.
Az emlékeztető óva int bizalmas információ, bármely olyan adat megosztásától, amelyet nem szeretnénk, ha a kiértékelők olvasnának, vagy a Google később felhasználna. Az elemzésekkel termékeik, szolgáltatásaik, gépitanulás-technológiáik minőségén kívánnak folyamatosan javítani – hangsúlyozzák.
A Google figyelmeztetése azért (is) fontos, mert szinte vakon megbízunk a generatív MI chatbotokban. Ez azért érdekes, mert általában odafigyelünk, óvatosak vagyunk appok telepítésével, engedélyek megadásával, a böngésző kiválasztásával, a Facebookon, a Google-on és más platformokon megosztott adatainkkal, MI-chatbotokkal szemben azonban megfeledkezünk az egészséges óvatosságról. Úgy érezzük, mintha privát beszélgetést folytatnánk egy segítőkész új baráttal, és hirtelen mindent meg akarunk osztani vele.
A Google erre figyelmeztet, és emlékeztet: (egyelőre) nem új baráttal, hanem jelenleg még személytelen mesterséges intelligenciával kommunikálunk.