A Maryland Egyetem kutatói amerikai álláshirdetéseket elemezve vizsgálták a mesterségesintelligencia-állások eloszlását. Nem meglepő módon Kaliforniában a legnagyobb a koncentráció, Washington D.C. és agglomerációja a második.
Az MI-állásokat nem pontosított nagy nyelvmodellel azonosították, definíciójuk szerint az MI-ismereteket, -tudást feltételező munkakörök tartoznak ebbe a kategóriába. Mindegyik munkakört a neki helyet adó szövetségi állam szerint kategorizálták. Az MI-gazdaság államonkénti növekedését és csökkenését a 2018-as és a 2023-as MI-állások összehasonlításával állapították meg. Államonként szintén kiszámolták, hány százalék állás betöltéséhez kellenek MI-ismeretek.
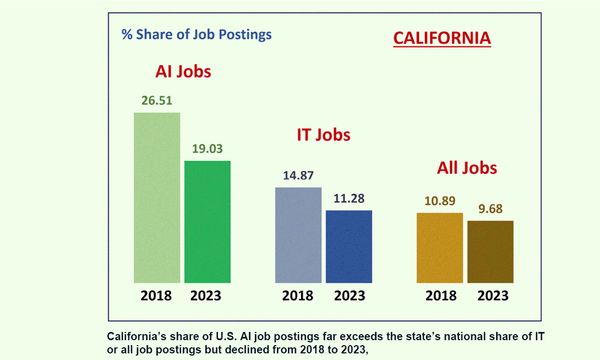
Változatlanul Kaliforniában jelenik meg a legtöbb MI-álláshirdetés, viszont az MI-állások száma összamerikai szinten a 2018-as 26 százalékról 2023-ra 19 százalékra, a nemzeti átlagnál 0,56 százalékkal nagyobb mértékben csökkent.
Washington államban, az Amazon és a Microsoft otthonában a 2018-as 13 százalékról 5 százalékra esett az MI-állások száma. Az államban megjelenő összes álláshirdetés egy százaléka ezzel együtt MI.
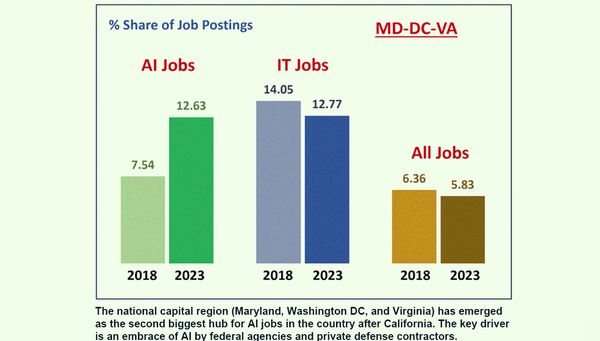
Maryland, Virginia és Washington D.C. együtt a 2018-as 7 százalékról 2023-ban 13 százalékot produkált. A növekedés a szövetségi kormány pozitív hozzáállásának tudható be. A kormányt támogató vállalatok újra elkezdtek MI-szakértőket alkalmazni a fővárosban.
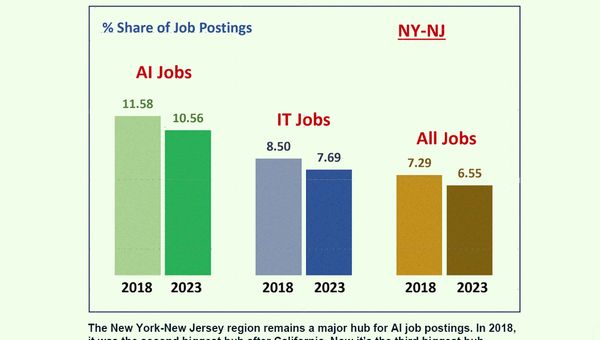
New York és New Jersey egyesített adatai 12-ről 11-re történő, egy százalékos csökkenésről tanúskodnak.
Az USA más részein szignifikáns növekedést mértek. Texasban és Floridában két-két százalékos (6-ról 8-ra, illetve 2-ről 4-re történő) emelkedést, míg a tizenkét középnyugati állam egyesített teljesítménye három százalékos (10-ről 13-ra történő) növekedés. Ezek az államok viszont az összes MI-álláshirdetésnek csak nagyon kis részét adták.
Egy, az USA nagyvárosainak MI-állásait felmérő 2021-es elemzés szerzői az álláshirdetések mellett a szövetségi ösztöndíjakat, a kutatásokról beszámoló tanulmányokat, a szabadalmi kérvényeket és a vállalatokat is figyelembe vették. Már akkor kiderült, hogy a Bay Area-n kívül is van, és egyre élénkebb az „MI-élet.” Most még nagyobb a földrajzi megoszlás.
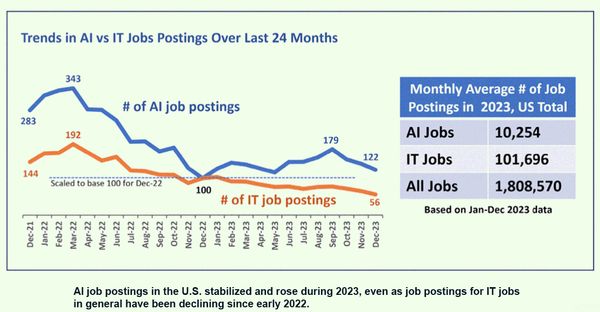
A beszámoló jó hír az álláskeresőknek: a bejáratott csomópontok változatlanul a legtöbb ajánlatot generálják, viszont máshol is javul a helyzet. Világtrend, hogy egyre több MI-szakértőre van szükség.